پردازش تصویر دیجیتال (Digital Image processing) به روشهایی گفته میشود که با دستکاری تصاویر دیجیتال از طریق استفاده از الگوریتم های کامپیوتری سروکار دارند. این یک مرحله پیش پردازش ضروری در بسیاری از برنامه ها، مانند تشخیص چهره، تشخیص اشیا و فشردهسازی تصویر است.
پردازش تصویر برای بهبود تصویر موجود یا حذف اطلاعات مهم از آن انجام میشود. این روش در برنامههای کاربردی بینایی کامپیوتری مبتنی بر یادگیری عمیق مهم است؛ برنامههایی که در آن چنین پیشپردازشی میتواند عملکرد یک مدل را به طور چشمگیری افزایش دهد. دستکاری تصاویر، به عنوان مثال، افزودن یا حذف اشیا به تصاویر، یکی دیگر از کاربردها به ویژه در صنعت سرگرمی و بازی است. در ادامه با ما همراه باشید تا به طور کامل با موضوع پردازش تصویر آشنا شویم.

انواع پردازش تصویر
هدف اصلی پردازش تصویر در پنج دسته مختلف قرار میگیرد که عبارتند از:
تجسم (Visualization) که دادههای پردازششده را به شیوهای قابل درک نشان میدهد، به عنوان مثال، با دادن فرم بصری به اشیایی که قابل مشاهده نیستند.
وضوح تصویر و بازیابی (Image Sharpening and Restoration) که کیفیت تصویر اصلی را افزایش میدهد.
بازیابی تصویر (Image Retrieval) به جستجوی تصاویر مشابه از یک پایگاه داده بزرگ کمک میکند.
اندازهگیری اشیا (Object Measurement): برای اندازهگیری اشیاء مختلف در یک تصویر استفاده میشود.
تشخیص الگو (Pattern Recognition): برای شناسایی الگوی اشیای مختلف موجود در یک تصویر است.

کاربرد های پردازش تصویر
بعضی از مهمترین زمینههایی که در آنها پردازش تصویر دیجیتال به طور گستردهای مورد استفاده قرار میگیرد، عبارتند از:
۱. استفاده از پردازش تصویر برای شارپ کردن و بازیابی تصویر
- بهبود وضوح و کیفیت تصاویر: فرآیند پردازش تصویر با حذف نویز، تاری و نقصها، عکسهای قدیمی را جان دوباره میبخشد و وضوح تصاویر تار را افزایش میدهد.
- رنگ و لعاب بخشیدن به عکسهای کهنه: با استفاده از ابزارهای پردازش تصویر میتوان با اصلاح رنگ و نور، به عکسهای قدیمی طراوت و شادابی بخشید.
۲. استفاده از پردازش تصویر در صنعت پزشکی
- تشخیص بیماریها: با پردازش تصویر و سپس تجزیه و تحلیل تصاویر پزشکی مانند MRI، CT اسکن و سونوگرافی، پزشکان میتوانند بیماریها را به طور دقیقتر و سریعتر تشخیص دهند.
- انجام جراحیهای کمتهاجمیتر: با کمک سیستمهای هدایت شده توسط تصویر، جراحان میتوانند با دقت و ظرافت بیشتری عمل کنند و خطر آسیب به بافتهای سالم را کاهش دهند.
- آنالیز بافت: با استفاده از پردازش تصویر در پزشکی، بررسی دقیق نمونههای بافتی به منظور تشخیص سرطان و سایر بیماریها آسانتر خواهد شد.
۳. استفاده از پردازش تصویر برای سنجش از دور
- نظارت بر محیط زیست: رصد تغییرات آب و هوایی، جنگلزدایی و بلایای طبیعی با استفاده از تصاویر ماهوارهای.
- نقشهبرداری و اندازهگیری: تهیه نقشههای دقیق از زمین، اندازهگیری مساحت و حجم اشیا و بررسی منابع طبیعی با استفاده از پردازش تصویر.
- کشف و مدیریت منابع: یافتن منابع جدید مانند نفت، گاز و مواد معدنی و مدیریت بهینهی آنها.
۴. استفاده از پردازش تصویر برای انتقال و رمزگذاری
- فشردهسازی تصاویر: کاهش حجم تصاویر برای ذخیرهسازی و انتقال آسانتر بدون افت کیفیت قابل توجه.
- رمزگذاری و رمزگشایی: محافظت از تصاویر در برابر دسترسی غیرمجاز با استفاده از الگوریتمهای رمزگذاری قدرتمند.
- انتقال تصاویر با پهنای باند کم: ارسال تصاویر با کیفیت بالا از طریق اینترنت یا شبکههای تلفن همراه با سرعت کم.
۵. بینایی ماشین و ربات به کمک پردازش تصویر
- رباتهای هوشمند: پردازش تصویر به رباتها قدرت بینایی میبخشد تا بتوانند محیط اطراف خود را درک کنند، اشیاء را شناسایی کنند و وظایف محوله را به طور مستقل انجام دهند.
- خودروهای خودران: با استفاده از دوربینها و پردازش تصویر، خودروهای خودران میتوانند محیط اطراف خود را درک کنند، موانع را تشخیص دهند و به طور ایمن حرکت کنند.
- سیستمهای امنیتی: با شناسایی چهره و اشیاء، میتوان از سیستمهای پردازش تصویر برای نظارت و کنترل محیط و ارتقای امنیت استفاده کرد.
۶. پردازش رنگ با استفاده از پردازش تصویر
- بهبود کیفیت تصاویر: تنظیم رنگ، کنتراست و روشنایی تصاویر برای ایجاد ظاهری جذابتر و واقعیتر.
- جداسازی اشیاء: تفکیک اشیاء مختلف در یک تصویر بر اساس رنگ و ویژگیهای ظاهری آنها.
- ایجاد جلوههای ویژه: خلق تصاویر و ویدیوهای خلاقانه با استفاده از تکنیکهای پردازش رنگ پیشرفته.
۷. الگوشناسی با استفاده از پردازش تصویر
- تشخیص چهره و اشیاء: شناسایی افراد، اشیاء و الگوهای خاص در تصاویر و ویدیوها.
- بازرسی و کنترل کیفیت: بررسی محصولات برای یافتن نقص و ایرادها با استفاده از سیستمهای پردازش تصویر مبتنی بر الگو.
- آنالیز دادههای تصویری: استخراج اطلاعات معنیدار از مجموعههای بزرگ تصاویر و ویدیوها.
۸. پردازش ویدیو با استفاده از پردازش تصویر
- ثابتسازی ویدیو: حذف لرزش و ارتعاشات ناخواسته از ویدیوها برای ایجاد تصویری روان و واضح.
- بهبود کیفیت ویدیو: ارتقای وضوح، رنگ و کنتراست ویدیوها برای تجربهی بصری بهتر.
- تجزیه و تحلیل ویدیو: استخراج اطلاعات مانند حرکت اشیاء، رفتار افراد و تعاملات آنها در ویدیوها با استفاده از پردازش تصویر.
البته، کاربردهای پردازش تصویر به موارد ذکر شده در بالا محدود نمیشود. این فناوری قدرتمند در حال نوآوری و گسترش به حوزههای مختلف است، از جمله:
- صنعت چاپ و نشر: پردازش تصویر برای ویرایش و ارتقای تصاویر، چاپ تصاویر با کیفیت بالا و تشخیص و حذف خطاها در چاپ استفاده میشود.
- صنعت بازی: پردازش تصویر برای خلق کارهای گرافیکی واقعیتر، انیمیشنهای روان و تجربهی بازیهای تعاملی و جذابتر به کار میرود.
- واقعیت افزوده و مجازی: پردازش تصویر نقش کلیدی در ادغام دنیای واقعی و مجازی ایفا میکند و به خلق تجربیات فراگیر و واقعی میانجامد.
- شبکههای اجتماعی: فیلترها و افکتهای تصویری که در شبکههای اجتماعی محبوب هستند، همگی مبتنی بر تکنیکهای پردازش تصویر هستند.
- آموزش و پژوهش: پردازش تصویر در زمینههای آموزشی برای تجسم مفاهیم علمی، ایجاد محتوای آموزشی تعاملی و تجزیه و تحلیل دادههای پژوهشی کاربرد دارد.
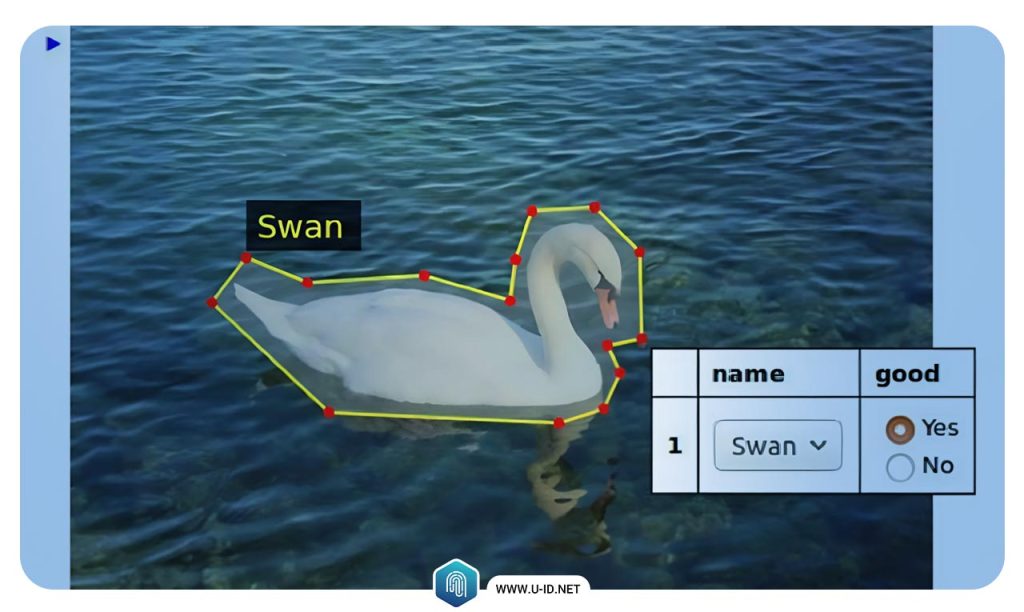
مزایای استفاده از پردازش تصویر
از مهمترین مزایای استفاده از پردازش تصویر میتوان به موارد زیر اشاره کرد:
- بهبود کیفیت تصویر: پردازش تصویر می تواند کیفیت تصویر را افزایش دهد و تصاویر را واضحتر، شفافتر و از نظر بصری جذابتر کند.
- اتوماسیون: پردازش تصویر امکان اتوماسیون کارهایی را فراهم میکند که اگر به صورت دستی انجام شوند، زمانبر هستند و امکان خطا در آنها وجود دارد، مانند تشخیص اشیا یا تشخیص نقص.
- استخراج اطلاعات: پردازش تصویر امکان استخراج اطلاعات ارزشمند از تصاویر را فراهم میکند که میتوان از آنها برای تصمیمگیری و تجزیه و تحلیل استفاده کرد.
- تشخیص پزشکی: پردازش تصویر در زمینه پزشکی، پردازش تصویر به تشخیص زودهنگام بیماری و درمان غیرتهاجمی کمک میکند.
- صرفهجویی در هزینهها: پردازش تصویر با کاهش نیاز به کار دستی و بهبود کارایی فرآیندها میتواند منجر به صرفهجویی در هزینهها در صنایع مختلف شود.
- تحقیقات علمی: پردازش تصویر در تحقیقات علمی بسیار مهم است و به محققان اجازه میدهد تا دادهها را به طور موثر تجزیه و تحلیل و تجسم کنند.
- امنیت پیشرفته: پردازش تصویر از طریق تشخیص چهره، تجزیه و تحلیل اثر انگشت و ردیابی اشیا، امنیت را افزایش میدهد.
- بیان خلاقانه: پردازش تصویر در صنعت هنر و سرگرمی، بیان خلاقانه و ایجاد جلوه های بصری خیره کننده را امکان پذیر می کند.
به طور خلاصه، پردازش تصویر یک زمینه همهکاره با کاربردهای متعدد است که از بهبود کیفیت تصویر تا فعال کردن اتوماسیون و تجزیه و تحلیل پیشرفته در حوزه های مختلف را شامل میشود. از مزایای آن میتوان به افزایش کیفیت تصویر، خودکارسازی وظایف و استخراج اطلاعات ارزشمند برای تصمیمگیری و تحقیق اشاره کرد.

پردازش تصویر در هوش مصنوعی
پردازش تصویر در هوش مصنوعی به مجموعهای از تکنیکها و الگوریتمها اشاره دارد که برای استخراج اطلاعات از تصاویر و ویدیوها به کار میروند. پردازش تصویر در هوش مصنوعی در اصل خود دارای دو زمینه پیشرفته است: هوش مصنوعی (AI) و بینایی کامپیوتر. پردازش تصویر با هوش مصنوعی، هنر و علم اعطای توانایی قابل توجه کامپیوترها برای درک، تفسیر و دستکاری دادههای بصری است که بسیار شبیه به سیستم بینایی انسان است. این حوزه شامل طیف گستردهای از وظایف میشود، از جمله:
- تشخیص شی: شناسایی و دستهبندی اشیاء موجود در یک تصویر یا ویدیو.
- تقسیمبندی تصویر: جداسازی اشیاء یا بخشهای مختلف یک تصویر.
- استخراج ویژگی: استخراج ویژگیهای کلیدی از تصاویر، مانند شکل، رنگ و بافت.
- تشخیص ناهنجاری: شناسایی تصاویر یا ویدیوهایی که از الگوی عادی منحرف میشوند.
- بهبود تصویر: بهبود کیفیت تصاویر با حذف نویز یا بازسازی بخشهای از دست رفته.
- افزایش کیفیت تصویر: ارتقای کیفیت تصاویر با روشهایی مانند شارپ کردن یا افزایش وضوح.
هوش مصنوعی، به ویژه یادگیری عمیق، نقش مهمی در پردازش تصویر ایفا میکند. شبکههای عصبی مصنوعی میتوانند از حجم عظیمی از دادههای تصویری برای یادگیری الگوها و انجام وظایف پردازش تصویر با دقت و کارایی بالا استفاده کنند.

تحلیل عکس با هوش مصنوعی
تحلیل عکس با هوش مصنوعی (Image Analysis using AI) که به آن بینایی کامپیوتری یا بینایی ماشین نیز گفته میشود، حوزهای جذاب و رو به رشد در هوش مصنوعی است که به کامپیوترها توانایی درک و استخراج اطلاعات از تصاویر و ویدیوها را میدهد. این فناوری طیف گستردهای از کاربردها را در زمینههای مختلف از جمله پزشکی، امنیتی، کشاورزی، خرده فروشی و سرگرمی داراست.
مقاله پیشنهادی: هوش مصنوعی چیست
اگر میپرسید که نحوه عملکرد تحلیل عکس با هوش مصنوعی چگونه است، باید گفت سیستمهای تحلیل عکس با هوش مصنوعی از الگوریتمهای پیچیدهای برای یادگیری از حجم عظیمی از دادههای تصویری استفاده میکنند. این دادهها شامل تصاویر برچسبگذاری شدهای هستند که در آنها اشیاء، افراد، صحنهها و سایر مفاهیم بصری مشخص شدهاند. الگوریتمها با تجزیه و تحلیل این دادهها، یاد میگیرند که الگوها و روابط بین پیکسلها را در تصاویر شناسایی کنند.
برخی از کاربردهای رایج تحلیل عکس با هوش مصنوعی عبارتند از:
- تشخیص اشیاء: شناسایی و طبقهبندی اشیاء موجود در یک تصویر، مانند افراد، حیوانات، وسایل نقلیه و غیره.
- تشخیص چهره: شناسایی و احراز هویت افراد در تصاویر و ویدیوها.
- تقسیمبندی تصویر: جداسازی اشیاء یا مناطق مختلف در یک تصویر.
- استخراج متن: استخراج متن از تصاویر، مانند تابلوهای تبلیغاتی یا اسناد.
- تشخیص حالات چهره: تشخیص احساسات افراد در تصاویر.
- ایجاد زیرنویس خودکار: ایجاد شرح و توضیحات خودکار برای تصاویر.
مقاله پیشنهادی: فناوری تطبیق یا تشخیص چهره در احراز هویت یوآیدی
مزایای تحلیل عکس با هوش مصنوعی
از مهمترین مزایای تحلیل عکس با هوش مصنوعی میتوان به موارد زیر اشاره کرد:
- دقت: سیستمهای هوش مصنوعی میتوانند تصاویر را با دقت بالایی تجزیه و تحلیل کنند و اشیاء و مفاهیم را با جزئیات دقیق شناسایی کنند.
- سرعت: الگوریتمهای هوش مصنوعی میتوانند تصاویر را به سرعت پردازش کنند و اطلاعات را در عرض چند ثانیه استخراج کنند.
- مقیاسپذیری: سیستمهای هوش مصنوعی میتوانند برای تجزیه و تحلیل حجم عظیمی از تصاویر بدون نیاز به دخالت انسان به کار گرفته شوند.

مراحل پردازش تصویر در هوش مصنوعی
پردازش دیجیتالی تصاویر شامل هشت مرحله کلیدی است. در ادامه به بررسی هر یک از این مراحل میپردازیم:
- به دست آوردن تصویر: فرآیند به دست آوردن تصویر به وسیله یک گیرنده (از جمله دوربین) و تبدیل آن به یک وضعیت قابل مدیریت است. یک روش مشهور برای کسب تصویر، بریدن آن است. در کاربردی قیاسی، چندین ابزار متعارف کسب تصویر ساختهایم تا به مشتریان خود کمک کنیم مجموعه دادههای با کیفیتی برای آموزش مدلهای شبکه عصبی، جمعآوری کنند.
- افزایش کیفیت تصویر: کیفیت تصویر را بهبود میدهد تا اطلاعات پنهان را برای پردازش بیشتر، از آن استخراج کند.
- ترمیم تصویر: این فرآیند نیز موجب بهبود کیفیت تصویر میشود که بیشتر به وسیله برداشتن خرابیهای احتمالی انجام میشود تا نسخه شفافتری از تصویر به دست آید. این فرآیند بیشتر بر اساس مدلهای ریاضیاتی و احتمالی به کار میرود و میتواند برای از بین بردن تیرگی، نویز، پیکسلهای جا افتاده، فوکوس اشتباه دوربین، نقاط سفید در تصویر و سایر خرابیهایی به کار رود که تاثیری منفی بر آموزش شبکه عصبی دارند.
- پردازش تصویر رنگی: شامل پردازش تصاویر رنگی و فضاهای مختلف رنگی است. با توجه به نوع تصویر، میتوانیم درباره پردازش شبه رنگها (هنگامی که رنگها، سایه دارند) یا پردازش RGB صحبت کنیم (برای تصاویری که با گیرنده کاملا رنگی به دست آمدند).
- فشردگی تصویر و فشار زدایی: امکان تغییر اندازه و وضوح تصویر را میدهد. فشردهسازی، موجب کاهش اندازه و وضوح تصویر میشود، درحالی که فشار زدایی، برای بازیابی تصویر در اندازه و وضوح واقعی آن به کار میرود. این تکنیکها اغلب در طول فرایند تقویت تصویر به کار میروند. وقتی دادههای چندانی ندارید، میتوانید مجموعه دادههای خود را با تصاویر تقویت شده، افزایش دهید. به این ترتیب، میتوانید شیوه تعمیم دادهها توسط مدل شبکه عصبی را بهبود ببخشید و اطمینان یابید نتایجی با کیفیت بالا به دست میآورید.
- پردازش ریختشناختی: این فرآیند شکلها و ساختارهای اشیا در تصویر را نشان میدهد. تکنیکهای پردازش ریختشناختی میتوانند هنگام ساخت مجموعه دادهها برای آموزش مدلهای هوش مصنوعی به کار روند. تحلیل و پردازش ریختشناختی میتواند در مرحله تفسیر به کار رود که در آن توضیح میدهید مدل هوش مصنوعی شما باید چه چیز را آشکار کند یا تشخیص دهد.
- تشخیص تصویر: به فرایند شناسایی ویژگیهای خاص اشیایی خاص در یک تصویر اشاره دارد. تشخیص تصویر با استفاده از هوش مصنوعی، اغلب از تکنیکهایی مانند آشکارسازی شی، تشخیص شی و تقسیمبندی استفاده میکند. راهحلهای هوش مصنوعی در این مرحله کاربرد بسیار خوبی دارند. وقتی همه این مراحل پردازش تصویر را تکمیل کردید، آمادهاید تا یک راهحل هوش مصنوعی واقعی را بسازید، یاد بگیرید و آزمایش کنید. فرایند توسعه یادگیری عمیق، شامل چرخه کاملی از عملیاتها از کسب داده تا به کارگیری مدل هوش مصنوعی توسعه یافته در سیستم نهایی است.
- بازنمایی و توضیح: به معنی فرآیند تصویریسازی و توضیح دادههای پردازش شده است. سیستمهای هوش مصنوعی به گونهای طراحی میشوند که تا حد ممکن، کارایی موثری داشته باشند. دادههای خام خروجی در یک سیستم هوش مصنوعی، شبیه به اعداد و مقادیری به نظر میرسند که اطلاعاتی را بازنمایی میکنند که مدل هوش مصنوعی برای تولید آن آموزش دیده است.
با این حال به دلیل عملکرد سیستم، یک شبکه عصبی عمیق معمولاً شامل هیچ بازنمایی از داده خروجی نیست. میتوانید با استفاده از ابزارهای تصویریسازی خاص، این اعداد و مقادیر را به تصاویر قابلخواندن و مناسب برای تحلیل بیشتر تبدیل کنید.

کتابخانههای منبع باز برای پردازش تصویر به وسیله هوش مصنوعی
کتابخانههای تصویری در کامپیوتر حاوی الگوریتمها و کارکردهای مشترک پردازش تصویر است. چندین کتابخانه منبع باز وجود دارد که میتوانید هنگام طراحی پردازش تصویر و ویژگیهای تصویر کامپیوتری از آن استفاده کنید:
- اوپن سی وی
- کتابخانه تصویری سازی
- مفسر تصویر VGG
اوپن سی وی
کتابخانه تصویر کامپیوتری منبع باز (Open CV) یک کتابخانه تصویری کامپیوتری محبوب است که صدها الگوریتمهای یادگیری ماشین و کامپیوتری و هزاران کارکرد برای تشکیل و پشتیبانی این الگوریتمها تهیه میکند. کتابخانه با واسطههای C++، جاوا و پایتون کار میکند و همه دسکتاپهای مشهور و سیستم عاملهای موبایل را پشتیبانی میکند.
اوپن سی وی شامل ماژولهای مختلفی است از جمله ماژول پردازش تصویر، ماژول آشکارسازی شی و ماژول یادگیری ماشین. با استفاده از این کتابخانه میتوانید دادههایی را از تصاویر به دست آورده، فشرده ساخته، تقویت کرده، و ذخیره نموده و استخراج کنید.
مقاله پیشنهادی: ماشین لرنینگ چیست
کتابخانه تصویری سازی
یک میانافزار با واسطه C++ برای اپلیکیشنهای دو بعدی و سه بعدی بر اساس کتابخانه گرافیک آزاد (OpenGL) است. این جعبه ابزار به شما امکان میدهد اپلیکیشنهای پرتابل و با عملکرد سطح بالا برای سیستم عاملهای ویندوز، لینوکس، و مک او اس بسازید. از آنجا که بسیاری از گروههای کتابخانه تصویری، نقشه برداری تک به تک شهودی با کارکردها و ویژگیهای کتابخانه OpenGL دارد، کار با این میانافزار آسان و راحت است.
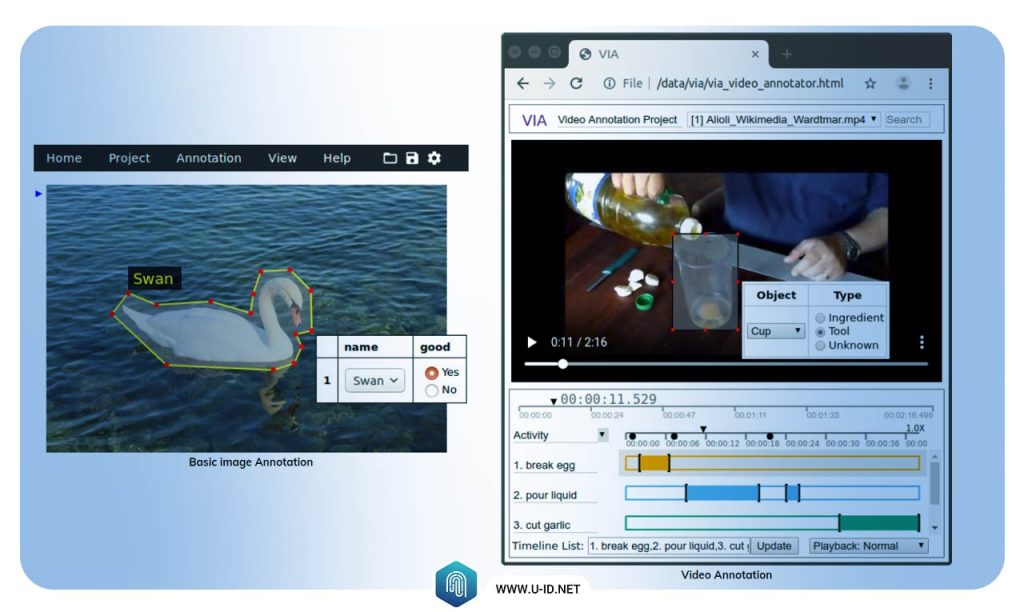
مفسر تصویر VGG
مفسر تصویر VGG (VIA) یک اپلیکیشن وب برای تفسیر شی است. این اپلیکیشن میتواند مستقیما در موتور جستجوی وب نصب شده و برای تصویر اشیای آشکارشده در تصاویر، صوت و ویدئوها به کار رود.
کار با VIA آسان است، نیازی به تنظیم یا نصب اضافی ندارد، و میتواند با هر جستجوگر مدرنی استفاده شود.
چارچوبهای یادگیری ماشین و پلتفرمهای پردازش تصویر
اگر بخواهید فراتر از استفاده ساده از الگوریتمهای هوش مصنوعی عمل کنید، میتوانید مدلهای یادگیری عمیق و متعارف برای پردازش تصویر را بسازید. برای اینکه پیشرفتتان سریعتر و آسانتر باشد، میتوانید از پلتفرمها و چارچوبهای ویژه استفاده کنید. در ادامه، نگاهی به بعضی از مشهورترین پلتفرمها داریم:
- تنسور فلو
- پای تورچ
- جعبه ابزار پردازش تصویر مطلب
- مایکروسافت کامپیوتر ویژن
- گوگل کلود ویژن
- همکاری گوگل (Colab)
تنسور فلو
تنسور فلو گوگل یک چارچوب مشهور منبع باز با پشتیبانی یادگیری ماشین و یادگیری عمیق است. با استفاده از تنسور فلو میتوانید مدلهای یادگیری عمیق متعارف را بسازید و یاد بگیرید. چارچوب شامل مجموعهای از کتابخانههاست از جمله مواردی که در پروژههای پردازش تصویر و اپلیکیشنهای ویژن کامپیوتر استفاده میشوند.
پای تورچ
پای تورچ یک چارچوب یادگیری عمیق منبع باز است که ابتدا توسط آزمایشگاه تحقیقات هوش مصنوعی فیسبوک (FAIR) ساخته شد. این چارچوب که بر اساس تورچ نوشته شده است، واسطههای پایتون، C++ و جاوا را به کار میگیرد.
میتوانید از پای تورچ برای ساخت اپلیکیشنهای پردازش زبان طبیعی و ویژن کامپیوتر استفاده کنید.
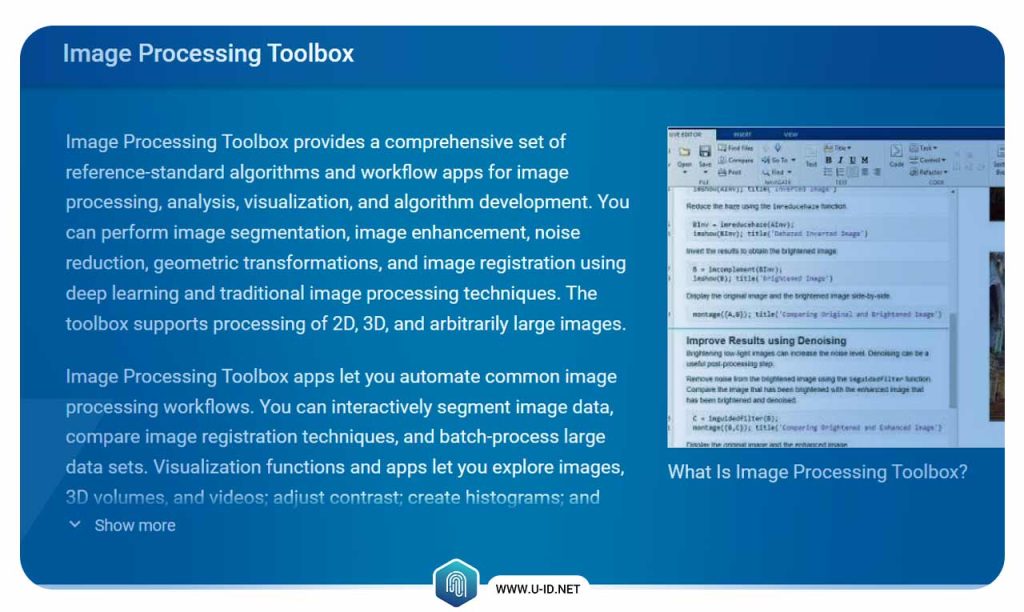
جعبه ابزار پردازش تصویر مطلب
مطلب، خلاصه آزمایشگاه ماتریس است. این نام یک پلتفرم مشهور برای حل مسئلههای علمی و ریاضی، و یک زبان برنامهنویسی است. این پلتفرم یک جعبه ابزار پردازش تصویر (IPT) تهیه میکند که شامل الگوریتمهای چندگانه و اپلیکیشنهای جریان کار برای پردازش، تصویریسازی و تحلیل تصاویر و طراحی الگوریتمهاست.
MATLAB IPT به شما این امکان را میدهد جریانهای کار رایج در پردازش تصویر را به شکل خودکار درآورید. این جعبه ابزار میتواند برای کاهش نویز، تقویت تصویر، تقسیمبندی تصویر، پردازش سه بعدی تصویر، و سایر کارها استفاده شود. بسیاری از کارکردهای IPT، نسل کد C/C++ را پشتیبانی میکنند، بنابراین میتوانند برای آرایش سیستمهای تصویر تعبیه شده و نمونههای دسکتاپ به کار روند.
MATLAB IPT یک پلتفرم منبع باز نیست اما آزمایش آن مجانی است.

مایکروسافت کامپیوتر ویژن
کامپیوتر ویژن یکی از خدمات سیستم کلود است که توسط مایکروسافت فراهم میشود و به وسیله آن میتوانید به الگوریتمهای پیشرفته ای برای پردازش تصویر و استخراج داده دسترسی یابید. با استفاده از خدمات آن میتوانید کارهای زیر را انجام دهید:
- تحلیل ویژگیهای تصویری و مشخصات یک تصویر
- اصلاح محتوای تصویر
- استخراج متن از تصویر
گوگل کلود ویژن
کلود ویژن بخشی از پلتفرم کلود گوگل است و مجموعهای از ویژگیهای پردازش تصویر را پیشنهاد میدهد. این پلتفرم یک API برای یکی کردن ویژگیهایی مانند نامگذاری تصویر و طبقهبندی آن، تعیین محل شی و تشخیص شی تهیه میکند.
کلود ویژن به شما امکان میدهد از مدلهای یادگیری ماشین از پیش آموخته استفاده کنید و مدلهای یادگیری ماشین متعارف را برای حل کارهای مختلف پردازش تصویر، بسازید و یاد بگیرید.
همکاری گوگل کولب (Collab)
همکاری گوگل که به نام کولب نیز شناخته میشود، یکی از خدمات مجانی کلود است که میتواند نه تنها برای بهبود مهارتهای کدگذاری بلکه برای طراحی اپلیکیشنهای یادگیری عمیق نیز استفاده شود.
کولب سبب میشود استفاده از کتابخانههای مشهوری مانند اوپن سیوی، کراس، و تنسور فلو در هنگام طراحی اپلیکیشن به وسیله هوش مصنوعی، آسانتر شود. این خدمات بر اساس شبکههای ژوپیتر است که به طراحان هوش مصنوعی امکان میدهد دانش و تخصص خود را با روشی آسان به اشتراک بگذارند. به علاوه، کولب برخلاف خدمات مشابه، منابع مجانی GPU تهیه میکند.
علاوه بر کتابخانهها، چارچوبها و پلتفرمهای مختلف، ممکن است به پایگاه داده بزرگی از تصاویر نیاز داشته باشید تا مدل خود را یاد گرفته و آزمایش کنید.
چندین پایگاه داده باز حاوی میلیونها تصویر برچسب خورده وجود دارد که میتوانید برای یادگیری الگوریتمها و اپلیکیشنهای یادگیری ماشین متعارف از آن استفاده کنید. ایمیجنت و پاسکال وک از جمله مشهورترین پایگاههای داده مجانی برای پردازش تصویر هستند.

استفاده از شبکههای عصبی برای پردازش تصویر
بسیاری از ابزارهایی که در بخش قبل درباره آن صحبت کردیم از هوش مصنوعی برای انجام کارهای پیچیده پردازش تصویر استفاده میکنند. درحقیقت، پیشرفتهایی که در هوش مصنوعی و یادگیری ماشینی انجام شده، یکی از دلایل پیشرفت چشمگیری است که در فناوری کامپیوتر ویژن اتفاق افتاده است و ما امروز شاهد آن هستیم.
بییشتر مدلهای موثر یادگیری ماشین برای پردازش تصویر از شبکههای عصبی و یادگیری عمیق استفاده میکنند. یادگیری عمیق از شبکههای عصبی برای انجام کارهای پیچیده استفاده میکند تا آنها را به روشی انجام دهد که مغز انسان آن کار را انجام میدهد.
انواع مختلف شبکههای عصبی برای انجام کارهای مختلف پردازش تصویر به کار گرفته میشود که از طبقهبندی ساده دوتایی (تصویر با معیارهای خاصی تطبیق دارد یا خیر) تا تقسیمبندی فوری را در بر میگیرد. انتخاب نوع صحیح و معماری شبکه عصبی، نقشی ضروری در به کارگیری یک روش موثر هوش مصنوعی برای پردازش تصویر دارد.
در ادامه، چندین شبکه عصبی مشهور را بررسی میکنیم و کارهایی که به بهترین شکل انجام میدهند را شرح میدهیم.
خدمات مرتبط
Custom.NET Development Services (خدمات توسعه نت)
شبکه عصبی پیچشی
شبکههای عصبی پیچشی (ConvNets یا CNNs) گروهی از شبکههای یادگیری عمیق هستند که به صورت ویژه برای پردازش تصویر ساخته شدند. درهرحال CNN با موفقیت در انواع مختلف داده به کار رفته است و فقط مختص تصویر نیست.
در این شبکهها، نورونها به همان شکلی سازمان دهی و متصل میشوند که در مغز انسان دیده میشود. برخلاف سایر شبکههای عصبی، CNN نیازمند عملیاتهای پردازش کمتری است. به علاوه، CNN به جای استفاده از فیلترهایی که به صورت دستی کار میکنند (هر چند میتواند از آنها نیز بهرهمند شود) میتوانند فیلترها و مشخصات ضروری را در طول آموزش، فرا گیرند. CNNها شبکههای عصبی چندلایه هستند که شامل لایههای ورودی و خروجی و نیز تعدادی بلوک لایه پنهان هستند که از موارد زیر تشکیل شده است:
- لایههای پیچشی: برای فیلترسازی تصویر ورودی و به دست آوردن ویژگیهای خاصی نظیر لبهها، منحنیها و رنگها به کار میروند.
- لایههای ادغام: بهبود آشکارسازی اشیایی که به شکل غیرمعمول قرار داده شدهاند.
- لایههای نرمالسازی (ReLU): بهبود عملکرد شبکه توسط نرمالسازی ورودیهای لایه قبلی
- لایههای کاملا متصل: لایههایی که نورونها در آن اتصالهای کاملی به همه موارد فعال شده در لایه قبلی دارند (مشابه شبکههای عصبی عادی).
همه لایههای CNN در سه بُعد (وزن، ارتفاع و عمق) آرایش مییابند و دو جزء دارند:
- استخراج ویژگیها
- طبقهبندی
در جزء اول، CNN پیچشهای چندگانه و کارهای ادغام انجام میشوند تا ویژگیهایی را آشکار کنند که سپس برای طبقهبندی تصویر به کار میروند.
در جزء دوم، با استفاده از ویژگیهای به دست آمده، الگوریتم شبکه تلاش میکند با محاسبه احتمال، پیشبینی کند شی داخل تصویر چیست.
CNN ها به صورت گسترده برای اجرای هوش مصنوعی در پردازش تصویر و حل مشکلاتی مانند پردازش سیگنال، طبقهبندی تصویر و تشخیص تصویر به کار میروند. انواع مختلفی از معماری CNN وجود دارد از جمله AlexNet, ZFNet, Faster R-CNN, GoogLeNet/Inception.
انتخاب معماری CNN بستگی به کاری دارد که قصد انجام آن را داریم. مثلا GoogLeNet در تشخیص برگ، دقت بالاتری نسبت به AlexNet یا CNN پایه نشان میدهد. همچنین اجرای GoogLeNet به دلیل تعداد لایههای بیشتر، به زمان بیشتری نیاز دارد.
Mask R-CNN یک شبکه عصبی عمیق بر پایه Faster R-CNN است که میتواند برای جداسازی اشیا در تصویر یا ویدئو پردازششده، به کار رود. این شبکه عصبی در دو مرحله کار میکند:
- تقسیمبندی شبکه عصبی : یک تصویر را پردازش میکند، نواحی که ممکن است حاوی اشیا باشد را آشکار میکند و پیشنهاداتی ارائه میکند.
- تولید ماسکها و کادرهای محدودکننده : شبکه، یک ماسک دوتایی برای هر گروه محاسبه کرده و نتایج نهایی را بر اساس این محاسبات، تولید میکند.
این مدل شبکه عصبی، انعطافپذیر و اصلاحپذیر است و در مقایسه با روشهای مشابه، عملکرد بهتری دارد. اما Mask R-CNN در پردازش زمان واقعی مشکل دارد. زیرا این شبکه عصبی نسبتا سنگین است و لایههای ماسک، کمی بالاسری به عملکرد آن اضافه میکنند و به ویژه در مقایسه با Faster R-CNN عملکرد کندتری دارد.
Mask R-CNN یکی از بهترین راهحلها برای تقسیمبندی فوری است. ما این معماری شبکه عصبی و مهارتهای خود در پردازش تصویر را در Apriorit به کار بردهایم تا کارهای بسیار پیچیدهای انجام دهیم. برای مثال پردازش دادههای تصاویر پزشکی و دادههای میکروسکوپی پزشکی. همچنین یک پلاگین را برای بهبود عملکرد این مدل از شبکه عصبی به کار بردهایم که عملکرد را به لطف استفاده از فناوری NVIDIA TensorRT افزایش داده است.
شبکه کاملا پیچشی
یک شبکه کاملا پیچشی (FCN) اولین بار توسط تیم محققان دانشگاه برکلی پیشنهاد شد. تفاوت اصلی بین CNN و FCN این است که FCN به جای لایهای پیچشی، یک لایه کاملا متصل عادی دارد. درنتیجه میتواند با سایزهای مختلف ورودی کار کند. همچنین FCN ها از کاهش ابعاد تصویر (پیچش راهراه) و افزایش ابعاد تصویر (پیچش جابجا شده) برای انجام عملیاتهای پیچش یا کانولو کردن با هزینه کمتر، استفاده میکنند.
یک شبکه عصبی کاملا پیچشی، برای تقسیمبندی تصویر در زمانی که شبکه عصبی، تصویر پردازش شده را به گروههای پیکسل چندگانه تقسیم میکند تا نامگذاری و طبقهبندی شوند، تناسب بسیار خوبی دارد. بعضی از مشهورترین FCN هایی که برای تقسیمبندی معنایی استفاده میشوند، DeepLab, RefineNet, Dilated Convolutions هستند.
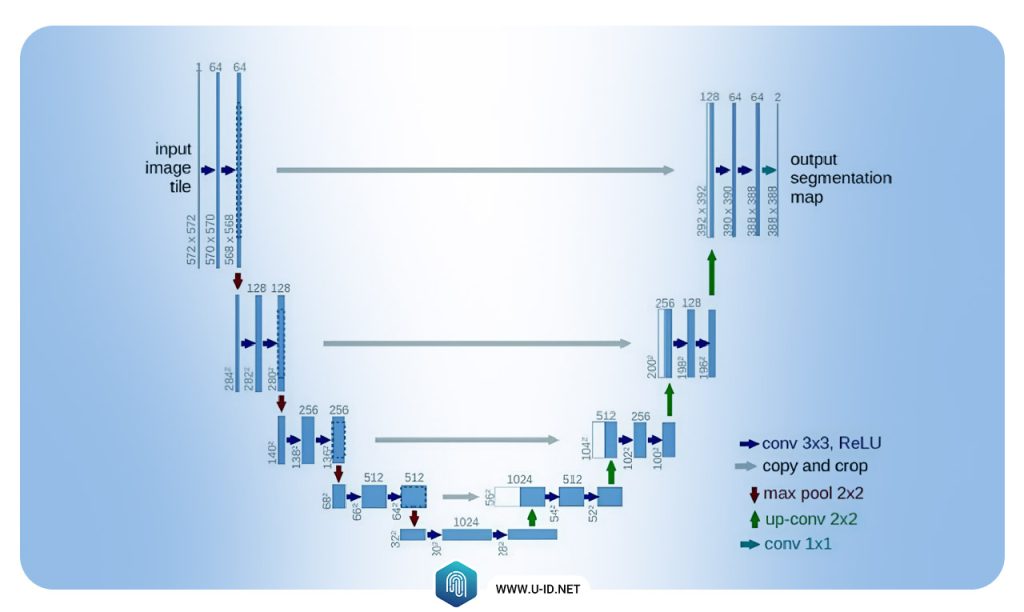
U-Net
U-Net یک شبکه عصبی پیچشی یا کانوله سازی است که امکان تقسیمبندی سریع و دقیق تصویر را فراهم میکند. برخلاف سایر شبکههای عصبی که در فهرست ما ارائه شد، U-Net به صورت اختصاصی برای تقسیمبندی تصویر زیستپزشکی طراحی شد. بنابراین تعجبی ندارد که U-Net برتر از Mask R-CNN است، به ویژه در کارهای پیچیدهای مانند پردازش تصویر پزشکی.
U-Net یک معماری U شکل دارد و کانالهای ویژگیهای آن در بخش افزایش ابعاد تصویر، بیشتر است. درنتیجه، شبکه، اطلاعات زمینه را در لایههایی با وضوح بالاتر منتشر میکند و بنابراین مسیر گسترده کم و بیش متقارنتری برای بخش انقباضی آن میسازد.
در Apriorit سیستمی با پایه U-Net را با موفقیت برای تقسیمبندی یک تصویر پزشکی اجرا کردیم. این روش به ما امکان داد نتایج متنوعتری از پردازش تصویر به دست آوریم و نتایج به دست آمده را، با دو سیستم مستقل، تحلیل کنیم. تحلیل بیشتر زمانی مفید است که یک متخصص این حوزه احساس کند اطمینان چندانی درباره نتیجه تقسیمبندی یک تصویر خاص ندارد.
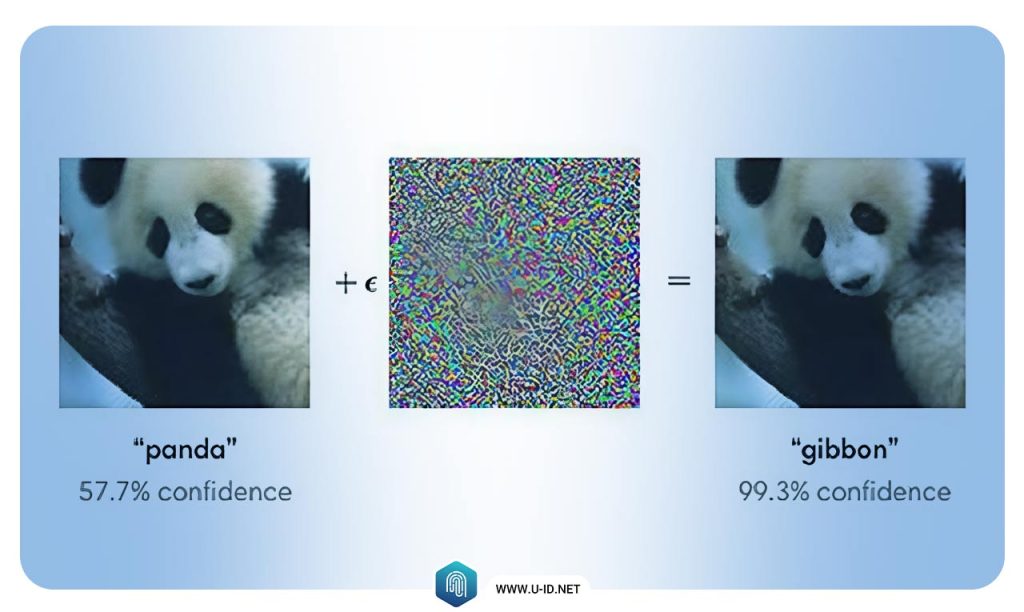
شبکههای زایای خصمانه
شبکههای زایای خصمانه (GAN) قرار است یکی از بزرگترین چالشهای شبکههای عصبی را حل کنند. و آن تصاویر خصمانه است.
تصاویر خصمانه با ایجاد خطاهای انبوه در شبکههای عصبی، شناخته شدهاند. مثلا اگر شبکه عصبی، لایهای از نویز تصویری به نام اختلال را در تصویر اصلی ایجاد کند، ممکن است موجب اشتباه شود. و هرچند تفاوت آن با مغز انسان تقریبا ناچیز است، اما الگوریتمهای کامپیوتری تلاش میکنند تصاویر خصمانه را به شکل درستی طبقهبندی کنند.
GAN ها شبکههای دوگانه هستند که شامل دو شبکهاند:
- یک تولیدکننده
- یک تفکیککننده
که در مقابل یکدیگر قرار میگیرند. شبکه تولیدکننده دادههای جدید تولید میکنند و شبکههای تفکیککننده، درستی این دادهها را ارزیابی میکنند.
به علاوه، برخلاف سایر شبکههای عصبی، GAN ها میتوانند به گونهای آموزش ببینند که دادههای جدیدی از جمله تصاویر، موسیقی و شعر را بسازند.
درهرحال از آنجا که هر یک از این مراحل، نیازمند پردازش مقادیر انبوهی از داده هستند، نمیتوانید آنها را به شکل دستی انجام دهید. در اینجا الگوریتمهای هوش مصنوعی و یادگیری ماشین (ML) بسیار مفید خواهند بود.
استفاده از هوش مصنوعی و یادگیری ماشین، سرعت پردازش داده و کیفیت نتیجه نهایی را افزایش میدهد. مثلا با کمک پلتفرمهای هوش مصنوعی میتوانیم کارهای پیچیدهای مانند آشکارسازی شی، تشخیص چهره و تشخیص متن را با موفقیت انجام دهیم. البته به منظور کسب نتایج با کیفیت، لازم است ابزارها و روشهای صحیحی را انتخاب کنیم.
یوآیدی به عنوان نوآورترین پلتفرم احراز هویت دیجیتال، از قدرت هوش مصنوعی، شامل یادگیری عمیق، برای ارائه خدماتی دقیق و امن احراز هویت بهره میبرد.
با یوآیدی، هویت خود را در کسری از ثانیه و با اطمینان کامل احراز کنید. خدمات یوآیدی شامل موارد زیر است
Source: claudeai.wiki
سوالات متداول
پردازش تصویر به مجموعهای از تکنیکها و الگوریتمها اشاره دارد که برای استخراج اطلاعات از تصاویر و ویدیوها به کار میروند. این حوزه شامل طیف گستردهای از وظایف میشود، از جمله تشخیص شی، تقسیمبندی تصویر، استخراج ویژگی، تشخیص ناهنجاری، ترمیم تصویر و افزایش تصویر.
از پردازش تصویر در چه زمینههایی استفاده میشود؟
کاربردهای پردازش تصویر بسیار متنوع هستند و در صنایع مختلفی از جمله پزشکی، امنیت، خودروهای خودران، کشاورزی و رسانههای اجتماعی به کار میرود.
نقش هوش مصنوعی در پردازش تصویر چیست؟
هوش مصنوعی، به ویژه یادگیری عمیق، نقش مهمی در پردازش تصویر ایفا میکند. شبکههای عصبی مصنوعی میتوانند از حجم عظیمی از دادههای تصویری برای یادگیری الگوها و انجام وظایف پردازش تصویر با دقت و کارایی بالا استفاده کنند.