

یادگیری تقویتی چیست؟
در تعریف یادگیری تقویتی Reinforcement Learning میتوان چنین گفت:
یادگیری تقویتی، دانش تصمیمگیری است. این حوزه به یادگیری رفتار بهینه در یک محیط برای به دست آوردن حداکثر پاداش میپردازد. این رفتار بهینه از طریق تعامل با محیط و مشاهدهی نحوهی پاسخ آن آموخته میشود؛ درست مانند کودکانی که با کشف دنیای اطراف خود، یاد میگیرند کدام اقدامات آنها را به هدفشان نزدیکتر میکند.
در نبود یک ناظر، یادگیرنده باید بهطور مستقل توالی از اقدامات را کشف کند که بیشترین پاداش را به همراه دارد. این فرآیند کشف، مشابه عمل آزمون و خطاست. کیفیت اقدامات، نه تنها با پاداش فوری، بلکه با پاداشهای تأخیری احتمالی نیز سنجیده میشود.
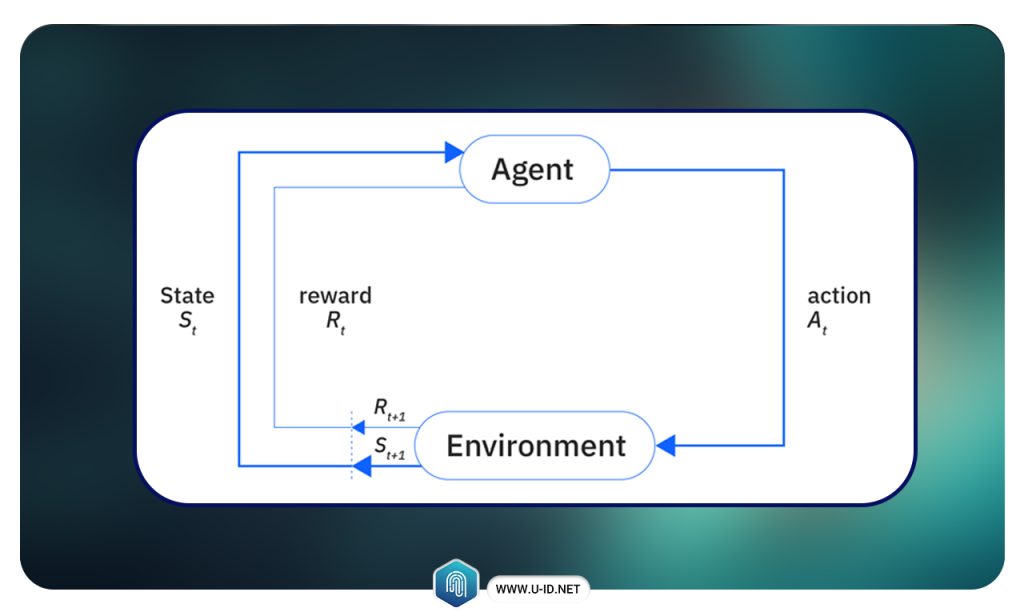
از آنجایی که یادگیری تقویتی میتواند بدون نیاز به ناظر، اقدامات مؤثر را در محیطی ناشناخته بیاموزد، الگوریتمی بسیار قدرتمند محسوب میشود.
تفاوت یادگیری عمیق و یادگیری تقویتی
یادگیری عمیق (Deep learning)، زیرشاخهای از یادگیری ماشین یا Machine Learning است که از شبکههای عصبی چندلایه، موسوم به شبکههای عصبی عمیق، برای شبیهسازی قدرت پیچیده تصمیمگیری مغز انسان استفاده میکند. امروزه، بیشتر کاربردهای هوش مصنوعی (AI) در زندگی ما، توسط نوعی از یادگیری عمیق پشتیبانی میشوند.
تفاوت اصلی بین یادگیری عمیق و یادگیری ماشین، ساختار معماری زیربنایی شبکههای عصبی است. مدلهای یادگیری ماشین سنتی (غیرعمیق)، از شبکههای عصبی ساده با یک یا دو لایه محاسباتی استفاده میکنند. در حالی که مدلهای یادگیری عمیق، برای آموزش مدلها از سه لایه یا بیشتر – و معمولاً صدها یا هزاران لایه – استفاده میکنند.
در حالی که مدلهای یادگیری نظارت شده برای تولید خروجیهای دقیق به دادههای ورودی ساختاریافته و برچسبخورده نیاز دارند، مدلهای یادگیری عمیق میتوانند از یادگیری بدون نظارت استفاده کنند. در یادگیری بدون نظارت، مدلهای یادگیری عمیق میتوانند ویژگیها، خصوصیات و روابط مورد نیاز برای تولید خروجیهای دقیق را از دادههای خام و بدون ساختار استخراج کنند. علاوه بر این، این مدلها حتی میتوانند خروجیهای خود را برای افزایش دقت، ارزیابی و اصلاح کنند.
مقایسهی مفاهیم، روشها و کاربردها
یادگیری تقویتی:
۱. یادگیری تقویتی، یک پارادایم از یادگیری ماشین است.
۲. یادگیری تقویتی به یک ناظر یا مجموعه داده از پیش برچسب خورده نیاز ندارد؛ در عوض، دادههای آموزشی را در قالب تجربه، از طریق تعامل با محیط و مشاهدهی پاسخ آن به دست میآورد.
۳. یادگیری تقویتی، عمل کردن را یاد میگیرد. در این روش، دادههای ورودی بهصورت توالیهایی از وضعیت، عمل و پاداش در نظر گرفته میشوند که به هم وابستهاند.
۴. الگوریتمهای یادگیری تقویتی، عمل کردن را از طریق تکرار آزمون و خطا و تابع پاداش یاد میگیرند، نه از طریق استخراج اطلاعات از الگوهای پنهان.
یادگیری عمیق:
۱. یادگیری عمیق، زیرشاخهای از یادگیری ماشین است که از شبکههای عصبی چندلایه، موسوم به شبکههای عصبی عمیق، برای شبیهسازی قدرت پیچیده تصمیمگیری مغز انسان استفاده میکند.
۲. در حالی که مدلهای یادگیری نظارتشده برای تولید خروجیهای دقیق به دادههای ورودی ساختاریافته و برچسبخورده نیاز دارند، مدلهای یادگیری عمیق میتوانند از یادگیری بدون نظارت استفاده کنند. در یادگیری بدون نظارت، مدلهای یادگیری عمیق میتوانند ویژگیها، خصوصیات و روابط مورد نیاز برای تولید خروجیهای دقیق را از دادههای خام و بدون ساختار استخراج کنند.
۳. مدلهای یادگیری عمیق برای یادگیری پیشبینی طراحی شدهاند. آنها فرض میکنند که هر رکورد از دادههای ورودی مستقل از سایر رکوردهای موجود در مجموعه داده است، اما هر رکورد یک مدل توزیع دادهی زیربنایی مشترک را محقق میکند.
همپوشانیهای یادگیری عمیق و یادگیری تقویتی:
هر دو، زیرشاخههای هوش مصنوعی و یادگیری ماشین هستند.
از یادگیری عمیق میتوان در یادگیری تقویتی برای بهبود فرآیند یادگیری و توانمندسازی عامل برای یادگیری سیاستهای بهینه در محیطهای پیچیده استفاده کرد.
مقاله پیشنهادی: تفاوت یادگیری عمیق و یادگیری ماشین
الگوریتم های یادگیری تقویتی

الگوریتمهای یادگیری تقویتی را میتوان به طور کلی به دو دستهی الگوریتمهای مدلمحور (Model-Based) و الگوریتمهای بدون مدل (Model-Free) تقسیم کرد:
۱. الگوریتمهای مدلمحور (Model-Based)
در این روشها، عامل ابتدا تلاش میکند یک مدل از محیط بسازد یا از مدل محیطی موجود استفاده کند. این مدل معمولاً شامل تابع انتقال حالت (transition model) و تابع پاداش است و پیشبینی میکند که پس از انجام یک عمل در یک وضعیت مشخص، چه وضعیت و پاداشی حاصل میشود. با کمک این مدل، عامل میتواند بدون تعامل مستقیم با محیط، سیاستهای مختلف را شبیهسازی و ارزیابی کند.
۲. الگوریتمهای بدون مدل (Model-Free)
در این روشها، عامل بدون داشتن دانش قبلی از محیط و بدون استفاده از مدل، مستقیماً از طریق تجربه و تعامل با محیط یاد میگیرد. عامل با استفاده از آزمون و خطا، سیاست مناسب را برای حداکثرسازی پاداش کسب میکند.
در کنار دستهبندی فوق، الگوریتمهای یادگیری تقویتی را میتوان بر اساس نوع سیاست یادگیری نیز به دو دسته تقسیم کرد:
۱. الگوریتمهای درونسیاستی (On-Policy): عامل از همان سیاستی یاد میگیرد که با آن محیط را تجربه میکند.
۲. الگوریتمهای برونسیاستی (Off-Policy): عامل میتواند از دادههایی که با سیاستی متفاوت از سیاست فعلی جمعآوری شدهاند، یاد بگیرد.
مهمترین الگوریتمهای یادگیری تقویتی
۱- یادگیری Q یا (Q-Learning)
Q-Learning یک الگوریتم برونسیاستی و بدون مدل است که با استفاده از جدول (Q-table) مقادیر Q برای جفتهای وضعیت-عمل را ذخیره و بهروزرسانی میکند. این الگوریتم با بهرهگیری از سیاستهای آزمندانه (greedy policy) سعی میکند پاداش تجمعی آینده را بیشینه کند.
۲- سارسا (SARSA)
الگوریتم SARSA (مخفف State-Action-Reward-State-Action) یک روش درونسیاستی است. برخلاف Q-Learning، این الگوریتم از همان سیاستی که عامل در زمان اجرا دنبال میکند، یاد میگیرد و Q-table را بر اساس جفتهای وضعیت-عمل فعلی بهروزرسانی میکند.
۳- شبکه Q عمیق (DQN)
DQN نسخهی توسعهیافتهی Q-Learning است که برای محیطهای با فضای وضعیت بزرگ بهجای Q-table از یک شبکهی عصبی عمیق استفاده میکند. این الگوریتم بدون مدل و برونسیاستی است و با بهرهگیری از تکنیکهایی مانند replay buffer و target network، پایداری آموزش را افزایش میدهد.
۴- الگوریتم گرادیان سیاست (Policy Gradient)
الگوریتمهای Policy Gradient بهجای یادگیری تابع مقدار، مستقیماً یک سیاست پارامتری شده را یاد میگیرند. این روشها معمولاً درون سیاستی هستند و برای محیطهایی با فضای عمل پیوسته یا ابعاد بالا بسیار مناسباند.
۵- الگوریتم بازیگر-منتقد (Actor-Critic)
این الگوریتم ترکیبی از دو روش مبتنی بر سیاست و مبتنی بر مقدار است. «بازیگر (Actor)» با استفاده از گرادیان سیاست، اقدام مناسب را انتخاب میکند و «منتقد (Critic)» با محاسبهی تابع مقدار، اقدامها را ارزیابی میکند. نسخههای مختلفی از این الگوریتم وجود دارد که میتوانند درونسیاستی یا برونسیاستی باشند (مانند A2C، A3C، DDPG، SAC).
۶- برنامهریزی پویا (Dynamic Programming)
در این روش فرض میشود که مدل کامل محیط (یعنی توابع انتقال و پاداش) در دسترس است. با استفاده از معادله بلمن (Bellman Equation)، عامل میتواند به صورت بازگشتی مقدار بهینه را برای هر وضعیت محاسبه و سیاست بهینه را استخراج کند.
۷- الگوریتم مونت کارلو (Monte Carlo)
الگوریتمهای مونت کارلو بدون مدل هستند و از طریق نمونهبرداری از اپیزودهای کامل یاد میگیرند. این روش با محاسبه میانگین بازده واقعی برای هر جفت وضعیت-عمل، تابع مقدار را برآورد میکند.
۸- یادگیری تفاضل زمانی (Temporal Difference – TD)
TD روشی بینابینی است که از ویژگیهای برنامهریزی پویا و الگوریتمهای مونت کارلو بهره میبرد. این الگوریتم پس از هر گام، با استفاده از اختلاف بین پاداش پیشبینی شده و واقعی (TD Error)، مقدار وضعیت را بهروزرسانی میکند. الگوریتمهایی مانند Q-Learning و SARSA نمونههایی از یادگیری TD هستند.
یادگیری تقویتی عمیق چیست؟
یادگیری تقویتی عمیق (Deep Reinforcement Learning – DRL) ترکیبی از یادگیری تقویتی (Reinforcement Learning) و یادگیری عمیق (Deep Learning) است. در این روش، مدل از شبکههای عصبی عمیق برای تقریب توابع ارزش (در الگوریتمهای مبتنی بر ارزش)، تابع سیاست (در الگوریتمهای مبتنی بر سیاست) یا هر دو (در ساختارهای Actor-Critic) استفاده میکند.
پیش از رواج یادگیری عمیق، الگوریتمهای یادگیری تقویتی برای کار با ورودیهای پیچیده نیاز به مهندسی دستی ویژگیها داشتند که این موضوع استفاده از آنها را به محیطهای ساده محدود میکرد. یادگیری عمیق این امکان را فراهم کرد که ویژگیهای معنادار به صورت خودکار از دادههای خام (مانند تصاویر یا سیگنالها) استخراج شوند. این امر باعث شد یادگیری تقویتی بتواند در محیطهای پیچیده، مقیاسپذیر و با فضای حالت بسیار بزرگ نیز عملکرد مناسبی داشته باشد.
مقاله پیشنهادی: دیپ لرنینگ یا یادگیری عمیق چیست
کاربردهای یادگیری تقویتی عمیق
- روباتیک:
DRL در آموزش رباتها برای انجام کارهای پیچیده مانند کنترل حرکتی دقیق، تقلید رفتار انسان، یا رانندگی خودکار کاربرد دارد. این رباتها میتوانند در محیطهای دنیای واقعی که پر از عدم قطعیت و تغییرات پویاست، عملکرد موفقی داشته باشند.
- پردازش زبان طبیعی (NLP):
در برخی کاربردهای پردازش زبان مانند بهینهسازی چتباتها، ترجمه ماشینی یا تولید متن، از DRL برای یادگیری پاسخهای بهتر بر اساس بازخوردهای کاربر و اهداف بلندمدت استفاده میشود.
- بازیها:
یکی از معروفترین نمونههای استفاده از DRL، عامل AlphaGo است که توسط DeepMind توسعه داده شد و توانست استادان حرفهای بازی Go را شکست دهد. همچنین از DRL در یادگیری بازیهای ویدیویی، تختهای و حتی استراتژیک استفاده میشود.
.
یادگیری تقویتی در هوش مصنوعی

یادگیری تقویتی، زیرشاخهای از یادگیری ماشین است. این روش به سیستمهای مبتنی بر هوش مصنوعی این امکان را میدهد تا در یک محیط پویا و با استفاده از آزمون و خطا، بر اساس پاداش دریافتی از اقداماتشان، سیاستهای بهینه را یاد بگیرند. در این رویکرد، عامل از طریق تعامل مستقیم با محیط، تجربه کسب میکند و تلاش مینماید پاداش تجمعی بلندمدت را به حداکثر برساند.
در مقایسه با سایر روشهای یادگیری ماشین، یادگیری تقویتی ظرفیت بالاتری برای تقلید فرآیندهای تصمیمگیری انسانمحور دارد و از این نظر، گامی مهم به سوی توسعه هوش مصنوعی عمومی (AGI) محسوب میگردد.
این الگوریتمها توانایی دنبال کردن اهداف بلندمدت را در عین کاوش مستقلانه محیط و آزمودن گزینههای مختلف دارا هستند. از این رو، یادگیری تقویتی در کاربردهایی مانند رباتیک، کنترل پهپادها و توسعه شبیهسازها نقش پررنگی ایفا میکند.
مقاله پیشنهادی: الگوریتم های یادگیری ماشین
تفاوت یادگیری تقویتی با یادگیری نظارتشده و یادگیری بدون نظارت
یادگیری تقویتی از نظر ساختار آموزشی و نوع دادههای مورد استفاده، تفاوتهای اساسی با دو رویکرد دیگر دارد:
یادگیری نظارت شده (Supervised Learning): بر اساس دادههای برچسبگذاری شده توسط ناظر آموزش میبیند. هدف این مدلها، پیشبینی خروجی صحیح برای دادههای ورودی جدید است. برای مثال، تشخیص ایمیل اسپم بر اساس نمونههای قبلی.
یادگیری بدون نظارت (Unsupervised Learning): با استفاده از دادههای بدون برچسب تلاش میکند الگوهای پنهان یا ساختارهای درونی دادهها را کشف کند. برای مثال، خوشهبندی مشتریان بر اساس رفتار خرید.
یادگیری تقویتی (Reinforcement Learning): بدون نیاز به دادههای برچسبگذاری شده، از طریق تعامل با محیط و دریافت پاداش یا تنبیه، سیاست تصمیمگیری بهینه را یاد میگیرد. این روش مبتنی بر تجربه، آزمون و خطاست و هدف آن یادگیری عمل مؤثر در شرایط مختلف میباشد.
اما تفاوتهای کلیدی:
۱. برخلاف یادگیری نظارت شده، یادگیری تقویتی به نمونههای برچسبگذاری شده نیازی ندارد.
۲. برخلاف یادگیری بدون نظارت، یادگیری تقویتی به جای کشف الگو، بر یادگیری بر پایه پاداش و تجربه تمرکز دارد.
۳. یادگیری تقویتی به طور خاص عمل کردن و تصمیمگیری در زمان واقعی را یاد میگیرد، در حالی که یادگیری نظارت شده و بدون نظارت بیشتر روی پیشبینی یا کشف الگو تمرکز دارند.
تفاوت یادگیری تقویتی و یادگیری تحت نظارت
از نظر نحوه عملکرد، میتوان تفاوتهای یادگیری تقویتی و یادگیری تحت نظارت را اینگونه بیان کرد:
| ویژگی | یادگیری تقویتی | یادگیری نظارت شده |
| رویکرد کلی | عامل با محیط تعامل میکند، بازخورد میگیرد و استراتژی خود را تنظیم میکند. | مدل از مجموعهای از دادههای برچسبگذاریشده یاد میگیرد. |
| نوع یادگیری | یادگیری از طریق آزمون و خطا (exploration & exploitation) | یادگیری تحت نظارت یک معلم (مثالهای برچسبخورده) |
| نقش بازخورد | بازخورد به شکل پاداش یا جریمه است. | خروجی صحیح به طور مستقیم به مدل داده میشود. |
| هدف نهایی | یادگیری سیاستی برای حداکثر سازی پاداشهای تجمعی در طول زمان | پیشبینی دقیق خروجی برای ورودیهای جدید |
مزایا و معایب یادگیری تقویتی و یادگیری تحت نظارت عبارتند از:
یادگیری تقویتی:
مزایا:
- مناسب برای مسائل پیچیده و محیطهای پویا
- قابلیت کشف استراتژیهای جدید از طریق تعامل
- عملکرد مؤثر در تصمیمگیری و کنترل
معایب:
- نیاز به زمان آموزش طولانی و داده زیاد
- طراحی تابع پاداش میتواند دشوار باشد
- برای مسائلی با داده برچسبدار ساده، بیشازحد پیچیده است
یادگیری نظارت شده:
مزایا:
- سادهتر و سریعتر در صورت دسترسی به دادههای برچسبگذاریشده
- تکنیکهای جاافتاده و دقیق برای طبقهبندی، رگرسیون و…
- امکان دستیابی به دقت بالا با داده کافی
معایب:
- نیاز به دادههای برچسبگذاریشده (زمانبر و پرهزینه)
- وابستگی زیاد به کیفیت دادهها
- عملکرد ضعیفتر در محیطهای پویا یا ناپایدار
کاربردهای یادگیری تقویتی
یادگیری تقویتی (Reinforcement Learning) در بسیاری از زمینههای پیشرفته مورد استفاده قرار گرفته و به توسعه سیستمهای هوشمند کمک شایانی کرده است. مهمترین کاربردهای آن عبارتاند از:
۱- کاربردهای یادگیری تقویتی در حوزه رباتیک و کنترل هوشمند
یادگیری تقویتی برای آموزش رباتها به منظور انجام وظایف در محیطهای پیچیده و پویا استفاده میشود. مثل:
- ناوبری ربات
- دستکاری اشیاء
- تعامل انسان و ربات
۲- کاربردهای یادگیری تقویتی در حوزه خودروهای خودران
یادگیری تقویتی نقش مهمی در توسعه وسایل نقلیه خودران ایفا میکند و یکی از تکنیکهای کلیدی در توسعه وسایل نقلیه خودران است. من جمله:
- تصمیمگیری برای رانندگی
- برنامهریزی مسیر
- مدیریت سناریوهای پیچیده ترافیکی
۳- کاربردهای یادگیری تقویتی در حوزه مالی و معاملات الگوریتمی
در امور مالی، یادگیری تقویتی برای موارد زیر به کار گرفته میشود:
- استراتژیهای معاملات الگوریتمی
- مدیریت سبد سهام
- مدیریت ریسک
۴- کاربردهای یادگیری تقویتی در حوزه پردازش زبان طبیعی
در حوزهی زبان طبیعی نیز یادگیری تقویتی نقش مؤثری ایفا کرده که میتوان به این موارد اشاره کرد:
- توسعه چتبات
- تولید مکالمه طبیعی و پاسخهای مناسب
- خلاصهسازی متن
۵- کاربردهای یادگیری تقویتی در دیگر زمینهها
علاوه بر زمینههای خاص ذکر شده، یادگیری تقویتی کاربردهای متنوعی دارد، از جمله:
الگوریتمهای یادگیری تقویتی در تسلط بر بازیهای پیچیده (مثلاً آلفاگو) موفقیت چشمگیری داشتهاند.
یادگیری تقویتی میتواند برای بهینهسازی برنامههای درمانی و تخصیص منابع مورد استفاده قرار گیرد.
یادگیری تقویتی میتواند شخصیسازی و اثربخشی سیستمها و پلتفرمهایی که در حوزه پیشنهاد محتوا فعالیت دارند را بهبود بخشد.
استفاده از هوش مصنوعی در زمینه احراز هویت
یوآیدی یک پلتفرم احراز هویت دیجیتال (e-KYC) در ایران است که با استفاده از فناوریهای هوش مصنوعی، فرآیند احراز هویت کاربران را به صورت آنلاین و در لحظه انجام میدهد.
یوآیدی به سازمانها و کسب و کارها کمک میکند تا فرآیندهای احراز هویت کاربران خود را به صورت آنلاین، سریع و با دقت بالا انجام دهند، از صورت گرفتن احراز هویتهای جعلی ممانعت کنند، هزینهها را کاهش داده و تجربه کاربری بهتری ارائه دهند.
برای دریافت وب سرویس های احراز هویت در کسبوکار خود، از طریق فرم با کارشناسان یوآیدی ارتباط بگیرید.
مزایا و معایب یادگیری تقویتی

یادگیری تقویتی، در کنار تمامی کاربردها و چالشهایی که دارد، دارای مزایا و معایبی خاصی است که در ادامه به آنها اشاره میکنیم:
مزایای یادگیری تقویتی:
- یادگیری از طریق تجربه مستقیم:
یادگیری تقویتی با تعامل مستقیم با محیط، تجربه کسب میکند و بر اساس پاداش (reward) یا تنبیه (penalty) یاد میگیرد که چه تصمیماتی بهتر هستند.
- قابلیت انطباق بالا با محیطهای پویا:
الگوریتمهای یادگیری تقویتی میتوانند با محیطهای ناشناخته یا متغیر سازگار شوند، زیرا به طور پیوسته در حال یادگیری از محیط هستند.
- مناسب برای مسائل تصمیمگیری دنبالهدار (Sequential Decision Making):
RL برای مسائلی مناسب است که نیاز به تصمیمگیری در طول زمان دارند، مانند بازیهای ویدیویی، رباتیک یا مدیریت منابع.
- استفاده در مسائل بدون داده برچسب خورده:
برخلاف یادگیری نظارت شده (Supervised Learning)، نیازی به دادههای برچسب خورده ندارد، زیرا خودش از طریق آزمون و خطا یاد میگیرد.
- قابلیت رسیدن به عملکرد سطح انسانی یا حتی فراتر:
الگوریتمهای یادگیری تقویتی در مواردی مانند بازی آتاری یا Go توانستهاند به سطحی برسند که عملکرد آنها از انسان نیز بهتر باشد.
- توانایی تصمیمگیری بهینه در محیطهای پیچیده:
یادگیری تقویتی میتواند رفتار بهینه را در یک محیط برای به دست آوردن حداکثر پاداش یاد بگیرد. این توانایی به ویژه در محیطهای پیچیده که یافتن راه حل بهینه از طریق روشهای سنتی دشوار است، ارزشمند است.
معایب یادگیری تقویتی:
- نیاز بالا به داده و زمان آموزش زیاد:
آموزش یک مدل RL ممکن است به هزاران یا میلیونها تکرار برای رسیدن به نتیجه مطلوب نیاز داشته باشد، مخصوصاً اگر محیط پیچیده باشد.
- هزینههای بالا برای تعامل با محیط واقعی:
در محیطهای واقعی مثل رباتیک، آزمون و خطای زیاد میتواند پرهزینه یا خطرناک باشد.
- نوسان زیاد در عملکرد (Instability):
بهدلیل وابستگی به پاداش، عملکرد الگوریتم ممکن است نوسان داشته باشد یا در برخی موارد به بهینه محلی (Local Optimum) گیر کند.
- سختی در طراحی تابع پاداش مناسب (Reward Function):
طراحی یک تابع پاداش دقیق و مؤثر چالشبرانگیز است، زیرا ممکن است پاداش نامناسب منجر به یادگیری رفتارهای اشتباه شود.
- عدم اطمینان در سیاست نهایی:
الگوریتمهای RL ممکن است در مسیر یادگیری به سیاستهای غیرقابل پیشبینی برسند که بررسی و تحلیل آنها دشوار است.
- دشواری در تعمیم یادگیری به محیطهای جدید:
اگر محیط جدید به طور قابل توجهی با محیط آموزشی متفاوت باشد، ممکن است عامل برای دستیابی به عملکرد مطلوب نیاز به آموزش مجدد یا تنظیمات جدید داشته باشد.
چالشهای کار با یادگیری تقویتی
یادگیری تقویتی، چالشهای منحصربهفردی دارد که میتواند این حوزه را به زمینهای پیچیده و گاه دشوار تبدیل کند. مثل:
- مسئله اکتشاف در برابر بهرهبرداری:
عوامل یادگیری تقویتی با یک دوراهی اساسی مواجه هستند: آیا محیط را برای کشف اقدامات جدید و پاداشهای بالقوه آنها «اکتشاف» کنند یا از دانشی که پیشتر کسب کردهاند برای به حداکثر رساندن پاداش فوری «بهرهبرداری» نمایند؟
یافتن تعادل مناسب میان اکتشاف و بهرهبرداری امری حیاتی است. اگر یک عامل صرفاً به بهرهبرداری بپردازد، ممکن است استراتژیهای بهتری را از دست بدهد. همچنین، اگر فقط به اکتشاف بپردازد، ممکن است فرآیند یادگیری هیچگاه به یک راهحل بهینه همگرا نشود.
- تنظیم مناسب پاداش و تأثیر آن بر عملکرد مدل:
طراحی توابع پاداش مؤثر، یک چالش اساسی در یادگیری تقویتی به شمار میرود. تابع پاداش، رفتار عامل را شکل میدهد و آن را به سوی هدف مطلوب هدایت میکند. اگر تابع پاداش به درستی طراحی نشده باشد، عامل ممکن است رفتارهای ناخواسته یا نامطلوب را بیاموزد.
تعریف یک تابع پاداش که به طور دقیق نتیجه مورد نظر را منعکس کند و از پیامدهای ناخواسته اجتناب ورزد، میتواند دشوار باشد.
- مسئله پاداشهای پراکنده:
در بسیاری از سناریوهای دنیای واقعی، پاداشها پراکنده هستند؛ به این معنا که عامل، بازخورد را فقط به ندرت دریافت میکند. این امر میتواند یادگیری را برای عامل بسیار دشوار سازد، زیرا ممکن است مدت زمان زیادی طول بکشد تا ارتباط بین اقداماتش با پاداشهای نهایی را درک کند.
پاداشهای پراکنده میتوانند روند یادگیری را به طور قابل توجهی کند کرده و نیازمند استفاده از تکنیکهای پیچیده برای غلبه بر آنها باشند.
- نیاز به محاسبات سنگین و منابع پردازشی قوی:
الگوریتمهای یادگیری تقویتی، به ویژه یادگیری تقویتی عمیق، اغلب به منابع محاسباتی قابل توجهی نیاز دارند. آموزش این مدلها میتواند زمانبر بوده و نیازمند سختافزار قدرتمندی نظیر پردازندههای گرافیکی (GPU) باشد. این پیچیدگی محاسباتی میتواند به عنوان مانعی در مسیر ورود به این حوزه عمل کند و کاربرد یادگیری تقویتی را در برخی موقعیتها محدود سازد.
سوالات متداول
از طریق تعامل یک عامل با محیط برای دستیابی به هدف، با یادگیری رفتار بهینه برای کسب حداکثر پاداش از طریق آزمون و خطا و مشاهده پاسخهای محیط.
الگوریتمهای Q-Learning، SARSA، Deep Q-Network (DQN) ،Policy Gradient Methods ،Actor-Critic Methods ،Dynamic Programming ،Monte Carlo Method و Temporal Difference (TD) Learning جزو بهترینها محسوب میشوند.
یادگیری تقویتی یک علم تصمیمگیری درباره یادگیری رفتار بهینه برای کسب حداکثر پاداش از طریق تعامل با محیط است، در حالی که یادگیری عمیق زیرشاخهای از یادگیری ماشین است که از شبکههای عصبی چندلایه برای شبیهسازی قدرت تصمیمگیری مغز انسان استفاده میکند.
مسئله اکتشاف در برابر بهرهبرداری، تنظیم مناسب پاداش، پاداشهای پراکنده و نیاز به محاسبات سنگین.
رباتیک و کنترل هوشمند، خودروهای خودران، مالی و معاملات الگوریتمی، پردازش زبان طبیعی، بازی، بهداشت و درمان و سیستمهای توصیهگر.





