۱۰ مورد از معروف ترین الگوریتمهای یادگیری ماشین
برای مبتدیان یادگیری ماشین که مشتاق درک اصول ماشین لرنینگ (Machine Learning) یا یادگیری ماشین هستند، در ادامه به ۱۰ الگوریتم های یادگیری ماشین در داده کاوی و مورد استفاده توسط دانشمندان علوم داده میپردازیم. این الگوریتمها عبارتند از:
- رگرسیون خطی (Linear Regression)
- رگرسیون لجستیک (Logistic Regression)
- آنالیز تشخیص خطی (Linear Discriminant Analysis)
- درختان طبقهبندی و رگرسیون (Classification and Regression Trees)
- بیز ساده (Naive Bayes)
- نزدیکترین همسایگان (KNN)
- کوانتیزاسیون برداری یادگیری (LVQ)
- ماشینهای بردار پشتیبانی (SVM)
- جنگل تصادفی (Random Forest)
- بوستینگ (Boosting)
- آدابوست (AdaBoost)
۱. رگرسیون خطی
رگرسیون خطی شاید یکی از شناختهشدهترین و رایجترین الگوریتمها در آمار و یادگیری ماشین باشد.
مدلسازی پیشبینیکننده اساساً مرتبط با به حداقل رساندن خطای یک مدل یا انجام دقیقترین پیشبینیهای ممکن، به قیمت توضیحپذیری است. الگوریتمها از بسیاری از زمینههای مختلف، از جمله آمار، قرض گرفته میشوند، دوباره استفاده میشوند و از آنها برای اهداف مختلف استفاده میشود.
نمایش رگرسیون خطی معادلهای است که خطی را توصیف میکند که بهترین تناسب را با رابطه بین متغیرهای ورودی (x) و متغیرهای خروجی (y)، با یافتن وزنهای خاص برای متغیرهای ورودی به نام ضرایب (B) دارد.
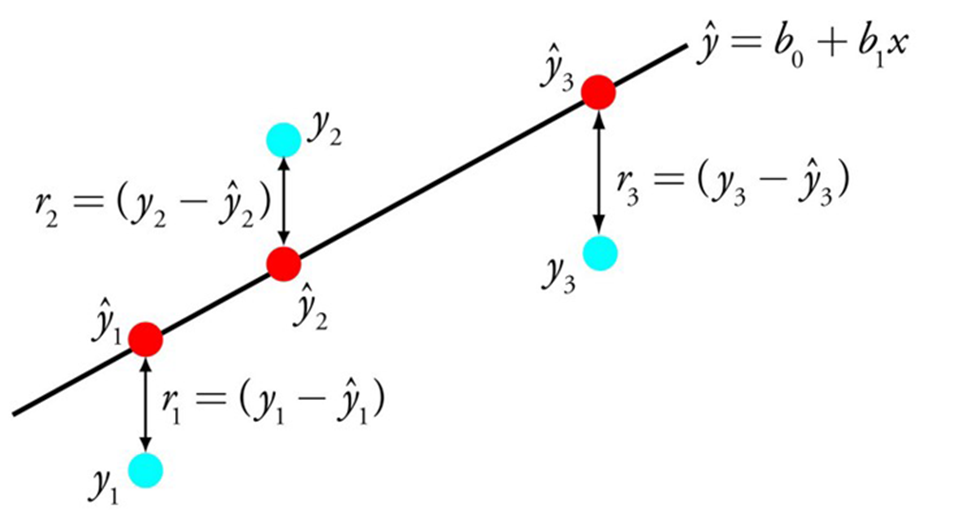
به عنوان مثال: y = B0 + B1 * x
ما y را با توجه به ورودی x پیشبینی میکنیم و هدف الگوریتم یادگیری رگرسیون خطی، یافتن مقادیر ضرایب B0 و B1 است.
تکنیکهای مختلفی را میتوان برای یادگیری مدل رگرسیون خطی از دادهها استفاده کرد، مانند راه حل جبر خطی برای حداقل مربعات معمولی و بهینهسازی نزول گرادیان.
رگرسیون خطی بیش از ۲۰۰ سال است که وجود دارد و به طور گسترده مورد مطالعه قرار میگیرد. برخی از قوانین سرانگشتی خوب هنگام استفاده از این تکنیک حذف متغیرهایی است که بسیار شبیه (همبسته) هستند. این یک تکنیک سریع و ساده و اولین الگوریتم خوب برای امتحان است.
۲. رگرسیون لجستیک
رگرسیون لجستیک تکنیک دیگری است که توسط یادگیری ماشین از حوزه آمار وام گرفته شده است. این روش برای مسائل طبقهبندی باینری (مشکلاتی با دو مقدار کلاس) است.
رگرسیون لجستیک مانند رگرسیون خطی است که هدف آن یافتن مقادیری برای ضرایب است که هر متغیر ورودی را وزن میکند. برخلاف رگرسیون خطی، پیشبینی خروجی با استفاده از یک تابع غیرخطی به نام تابع لجستیک تبدیل میشود.
تابع لجستیک مانند یک S بزرگ به نظر میرسد و هر مقداری را به محدوده ۰ تا ۱ تبدیل میکند. این عملکرد بسیار مفید است زیرا میتوانیم یک قانون را در خروجی تابع لجستیک اعمال کنیم تا مقادیر را به ۰ و ۱ تغییر دهیم (مثلاً اگر کمتر از ۰.۵ باشد پس خروجی ۱ است) و یک مقدار کلاس را پیشبینی کنیم.
بیشتر بخوانید: هوش مصنوعی یا AI چیست
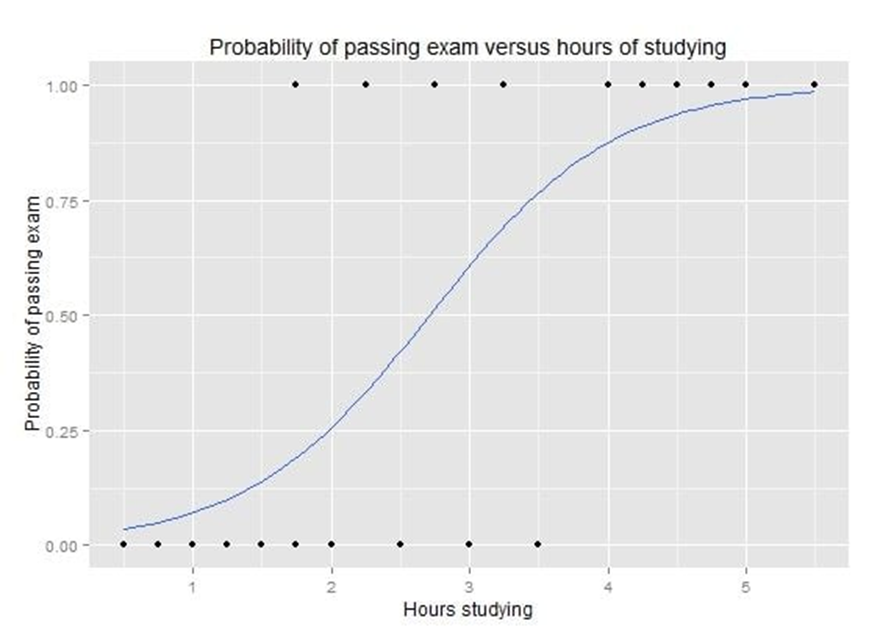
رگرسیون لجستیک: نمودار منحنی رگرسیون لجستیک که احتمال قبولی در امتحان را در مقابل ساعات مطالعه نشان میدهد.
به دلیل نحوه یادگیری مدل، پیشبینیهای انجامشده توسط رگرسیون لجستیک نیز میتواند به عنوان احتمال یک نمونه داده معین متعلق به کلاس ۰ یا کلاس ۱ مورد استفاده قرار گیرد. این امر میتواند برای مشکلاتی مفید باشد که در آن شما نیاز به ارائه دلایل منطقی بیشتر برای یک پیشبینی دارید.
رگرسیون لجستیک، مانند رگرسیون خطی، زمانی بهتر عمل میکند که ویژگیهایی را حذف کنید که با متغیر خروجی مرتبط نیستند و همچنین ویژگیهایی که بسیار شبیه (همبسته) به یکدیگر هستند. این یک مدل سریع برای یادگیری موثر در مسائل طبقه بندی باینری است.
۳. آنالیز تشخیص خطی
رگرسیون لجستیک یک الگوریتم یادگیری ماشین طبقهبندی است که به طور سنتی فقط به مسائل طبقهبندی دو کلاسه محدود می شود. اگر بیش از دو کلاس دارید، الگوریتم آنالیز تشخیص خطی (Linear Discriminant Analysis یا LDA) روش طبقهبندی خطی بهتری است.
الگوریتم LDA بسیار ساده است. این الگوریتم شامل ویژگیهای آماری دادههای شما است که برای هر کلاس محاسبه میشود. برای یک متغیر ورودی واحد شامل موارد زیر است:
- مقدار میانگین برای هر کلاس.
- واریانس محاسبه شده در تمام کلاسها.
بیشتر بخوانید: انواع هوش مصنوعی
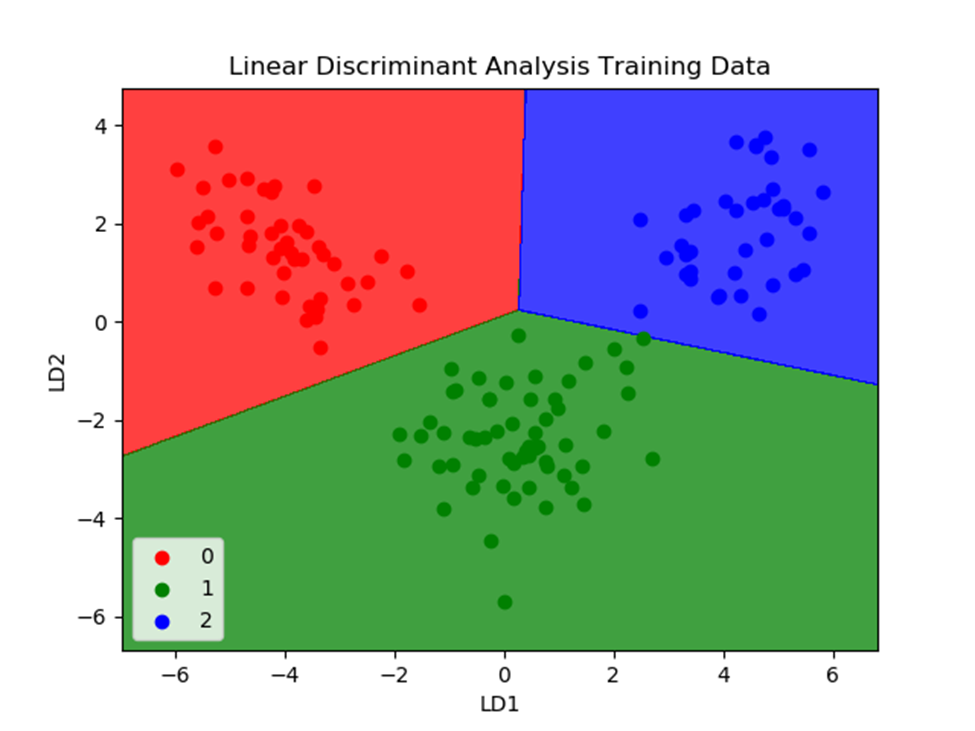
پیشبینیها با محاسبه یک مقدار متمایز برای هر کلاس و پیشبینی کلاس با بیشترین مقدار انجام میشود. این تکنیک فرض میکند که دادهها دارای توزیع گاوسی (منحنی زنگی) هستند، بنابراین ایده خوبی است که از قبل اطلاعات پرت را حذف کنید. این یک روش ساده و قدرتمند برای طبقهبندی مشکلات مدلسازی پیشبینی است.
۴. درختان طبقهبندی و رگرسیون
درختهای تصمیمگیری نوع مهمی از الگوریتمهای یادگیری ماشین برای مدلسازی پیشبینیکننده هستند.
نمایش مدل درخت تصمیم، یک درخت باینری است. این درخت باینری از الگوریتمها و ساختارهای داده ایجاد شده است. هر گره نشان دهنده یک متغیر ورودی واحد (x) و یک نقطه تقسیم روی آن متغیر است (با فرض اینکه متغیر عددی است).
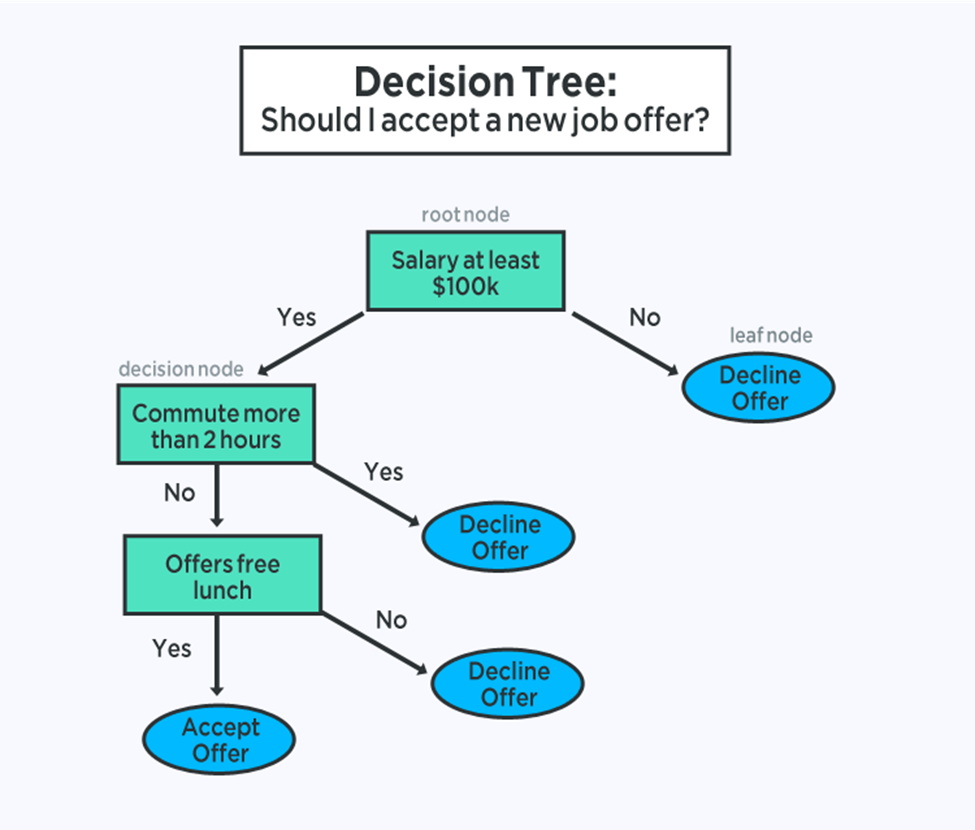
گرههای برگ درخت حاوی یک متغیر خروجی (y) هستند که برای پیشبینی استفاده میشود. پیشبینیها با پیشروی روی شکافهای درخت تا رسیدن به یک گره برگ و خروجی مقدار کلاس در آن گره برگ انجام میشود.
درختان تصمیم برای پیش بینی بسیار سریع عمل میکنند. آنها همچنین اغلب برای طیف گستردهای از مشکلات دقیق هستند و نیازی به آمادگی خاصی برای دادههای شما ندارند.
۵. بیز ساده
Naive Bayes یا بیز ساده یک الگوریتم یادگیری ماشین ساده اما بسیار قدرتمند برای مدل سازی پیش بینی است.
این مدل از دو نوع احتمال تشکیل شده است که میتوانند مستقیماً از داده های آموزشی شما محاسبه شوند: ۱) احتمال هر کلاس. و ۲) احتمال شرطی برای هر کلاس با توجه به هر مقدار x. پس از محاسبه، می توان از مدل احتمال برای پیش بینی دادههای جدید با استفاده از قضیه بیز استفاده کرد. زمانی که دادههای شما دارای ارزش واقعی هستند، معمول است که یک توزیع گاوسی (منحنی زنگی) را فرض کنید تا بتوانید به راحتی این احتمالات را تخمین بزنید.
بیز ساده از آن جهت ساده نامیده میشود که هر متغیر ورودی مستقل است. این یک فرض قوی و غیر واقعی برای داده های واقعی است، با این وجود، این تکنیک در طیف وسیعی از مسائل پیچیده بسیار موثر است.
۶. کی-نزدیکترین همسایه
الگوریتم KNN (K-NEAREST NEIGHBORS) بسیار ساده و بسیار موثر است. نمایش مدل برای KNN، کل مجموعه داده آموزشی است.
پیشبینیها برای یک نقطه داده جدید با جستجو در کل مجموعه آموزشی برای K مشابهترین نمونهها (همسایهها) و خلاصه کردن متغیر خروجی برای آن نمونههای K انجام میشود. برای مسائل رگرسیون، این نمونه ممکن است متغیر خروجی متوسط باشد، برای مسائل طبقهبندی ممکن است مقدار کلاس حالت باشد.
ترفند کار در چگونگی تعیین شباهت بین نمونه های داده است. سادهترین تکنیک اگر ویژگیهای شما همه در یک مقیاس هستند (مثلاً همه در اینچ) استفاده از فاصله اقلیدسی است، عددی که میتوانید مستقیماً بر اساس تفاوت بین هر متغیر ورودی محاسبه کنید.
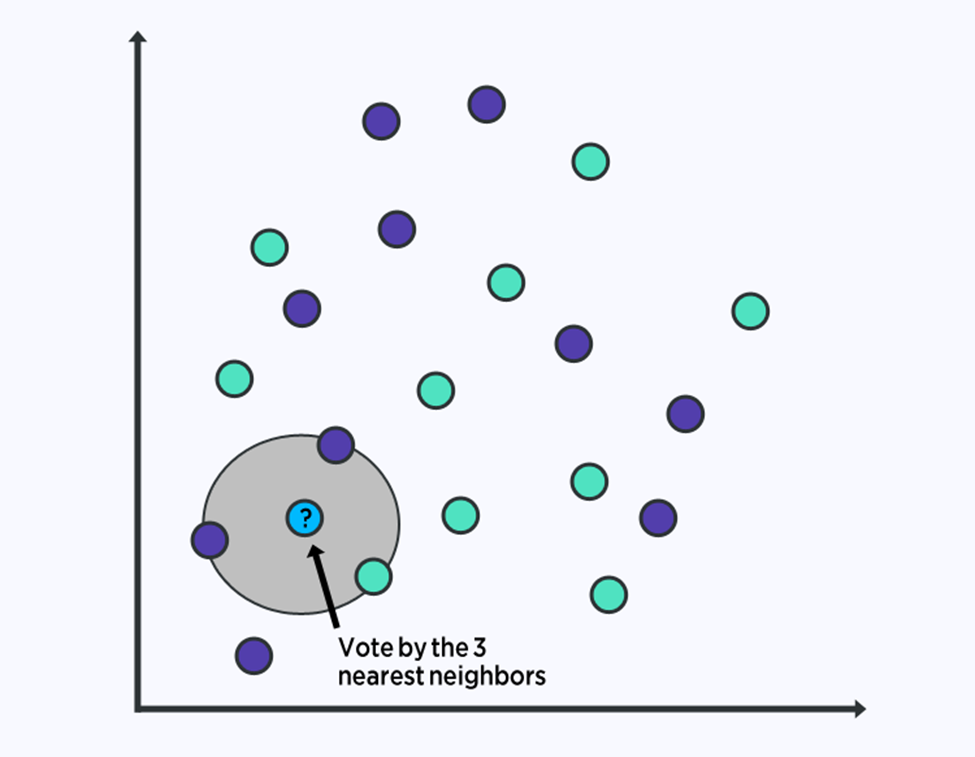
KNN میتواند به حافظه یا فضای زیادی برای ذخیره همه دادهها نیاز داشته باشد، اما فقط زمانی محاسبه (یا یادگیری) را انجام میدهد که به پیشبینی نیاز باشد، یعنی درست به موقع. همچنین میتوانید نمونههای آموزشی خود را در طول زمان بهروزرسانی و مدیریت کنید تا پیشبینیها دقیق باشد.
ایده فاصله یا نزدیکی میتواند در ابعاد بسیار بالا (تعداد زیادی از متغیرهای ورودی) شکسته شود که میتواند بر عملکرد الگوریتم روی مشکل شما تأثیر منفی بگذارد. این مقوله نفرین ابعادی (Curse of dimensionality) نامیده میشود. پیشنهاد میشود فقط از آن دسته از متغیرهای ورودی استفاده کنید که بیشترین ارتباط را با پیشبینی متغیر خروجی دارند.
۷. کوانتیزاسیون برداری یادگیری
یکی از نقاط ضعف الگوریتم یادگیری ماشین K-Nearest Neighbors این است که باید به کل مجموعه داده آموزشی خود تکیه کنید. الگوریتم کوانتیزاسیون بردار یادگیری (یا به اختصار LVQ) یک الگوریتم شبکه عصبی مصنوعی است که به شما این امکان را میدهد تا چند نمونه آموزشی را انتخاب کنید و دقیقاً یاد میگیرد که آن نمونهها چگونه باید باشند.
نمایش LVQ مجموعهای از بردارهای کتاب کد است. اینها در ابتدا بهطور تصادفی انتخاب میشوند و برای جمعبندی مجموعه دادههای آموزشی در تعدادی از تکرارهای الگوریتم یادگیری، تطبیق داده میشوند. پس از یادگیری، از بردارهای کتاب کد می توان برای پیش بینی درست مانند K-Nearest Neighbors استفاده کرد. مشابهترین همسایه (بهترین منطبق بردار کتاب کد) با محاسبه فاصله بین هر بردار کتاب کد و نمونه داده جدید پیدا میشود. سپس مقدار کلاس یا (مقدار واقعی در صورت رگرسیون) برای بهترین واحد تطبیق به عنوان پیشبینی برگردانده میشود. بهترین نتایج در صورتی به دست میآید که دادههای خود را تغییر مقیاس دهید تا محدوده مشابهی داشته باشند، مثلاً بین ۰ و ۱.
اگر متوجه شدید که KNN نتایج خوبی در مجموعه داده شما ارائه می دهد، سعی کنید از LVQ برای کاهش نیازهای حافظه ذخیرهسازی کل مجموعه داده آموزشی استفاده کنید.
۸. ماشینهای بردار پشتیبانی
ماشینهای بردار پشتیبانی شاید یکی از محبوبترین الگوریتمهای یادگیری ماشین باشند که در مورد آن صحبت شده است.
هایپرپلن خطی است که فضای متغیر ورودی را تقسیم می کند. در SVM، یک ابر صفحه انتخاب میشود تا نقاط در فضای متغیر ورودی را به بهترین نحو از هم جدا کند، کلاس ۰ یا کلاس ۱. در دوبعدی، میتوانید این را به صورت یک خط تجسم کنید و فرض کنید همه نقاط ورودی ما میتوانند با این خط کاملا از هم جدا شوند. الگوریتم یادگیری SVM ضرایبی را پیدا میکند که منجر به بهترین جداسازی کلاسها توسط ابر صفحه میشود.
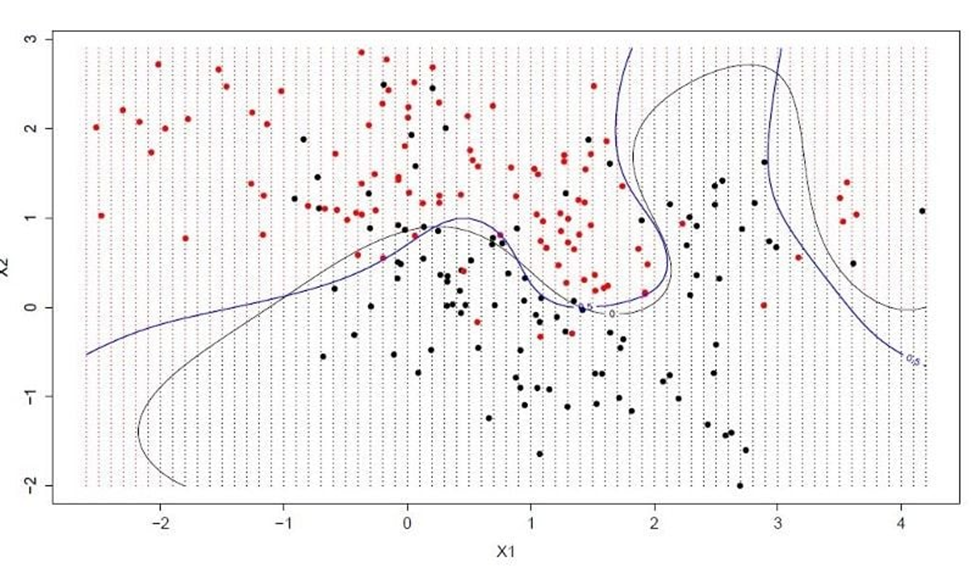
فاصله بین ابر صفحه و نزدیکترین نقاط داده حاشیه نامیده میشود. بهترین یا بهینهترین هایپرپلنی که میتواند این دو کلاس را از هم جدا کند، خطی است که بیشترین حاشیه را دارد. فقط این نکات در تعریف هایپرپلن و در ساخت طبقهبندیکننده مرتبط هستند. به این نقاط، بردارهای پشتیبان میگویند. آنها هایپرپلن را پشتیبانی یا تعریف میکنند. در عمل، از یک الگوریتم بهینهسازی برای یافتن مقادیر ضرایبی استفاده میشود که حاشیه را به حداکثر میرساند.
SVM ممکن است یکی از قدرتمندترین طبقهبندیکنندههای خارج از جعبه باشد و ارزش امتحان کردن روی مجموعه دادههای شما را داشته باشد.
۹. بگینگ و جنگل تصادفی
جنگل تصادفی یکی از محبوبترین و قدرتمندترین الگوریتم های یادگیری ماشین است. این یک نوع الگوریتم یادگیری ماشین گروهی است که Bootstrap Aggregation یا کیسهبندی (bagging) نامیده میشود.
Bootstrap Aggregation یک روش آماری قدرتمند برای تخمین کمیت از نمونه داده است؛ مانند یک میانگین. شما نمونههای زیادی از دادههای خود را می گیرید، میانگین را محاسبه میکنید، سپس تمام مقادیر میانگین خود را میانگین میگیرید تا تخمین بهتری از میانگین واقعی به شما ارائه دهد.
در کیسهبندی یا بگینگ، از همین رویکرد استفاده میشود، اما در عوض برای تخمین کل مدلهای آماری، معمولاً درختهای تصمیمگیری استفاده میشوند. نمونههای متعددی از داده های آموزشی شما گرفته میشود، سپس برای هر نمونه داده مدلهایی ساخته میشود. زمانی که نیاز به پیشبینی برای دادههای جدید دارید، هر مدل یک پیشبینی میکند و پیشبینیها میانگین میشوند تا تخمین بهتری از مقدار خروجی واقعی ارائه کنند.
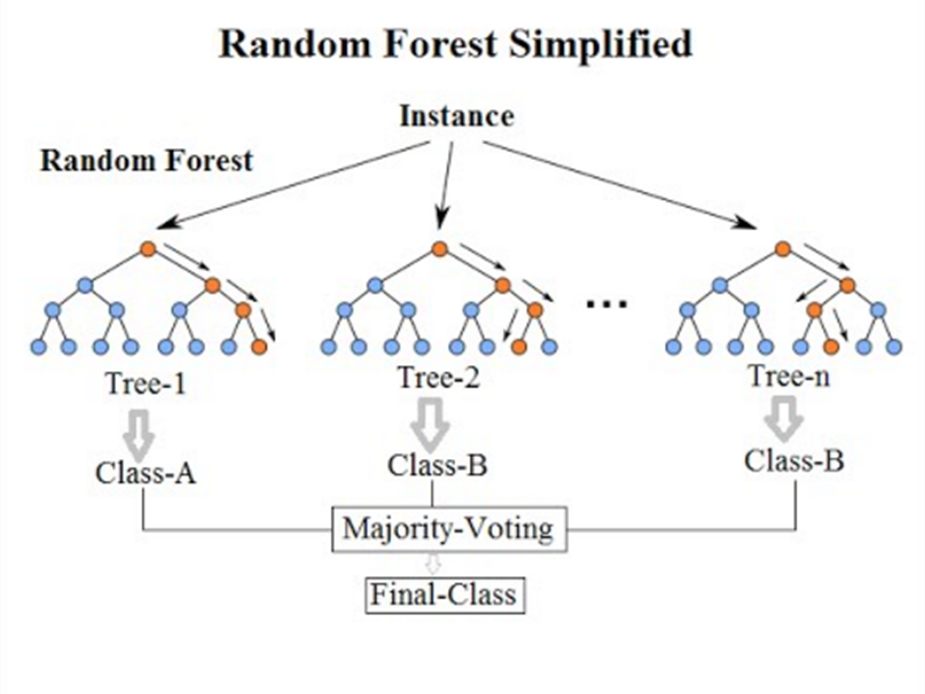
جنگل تصادفی
جنگل تصادفی تغییری در این رویکرد است که در آن درختهای تصمیم ایجاد میشوند تا به جای انتخاب نقاط تقسیم بهینه، تقسیمهای غیربهینه با معرفی تصادفی ایجاد شوند.
بنابراین، مدلهای ایجاد شده برای هر نمونه از دادهها، متفاوتتر از آنچه هستند که در غیر این صورت بودند، اما هنوز هم به روشهای منحصربهفرد و متفاوت خود دقیق هستند. ترکیب پیشبینیهای آنها منجر به برآورد بهتری از مقدار خروجی واقعی میشود.
اگر با الگوریتمی با واریانس بالا (مانند درختان تصمیم) نتایج خوبی به دست آورید، اغلب می توانید با بستهبندی آن الگوریتم نتایج بهتری به دست آورید.
۱۰. تقویت و آدابوست
Boosting یک تکنیک مجموعهای است که تلاش میکند یک طبقهبندی قوی از تعدادی طبقهبندیکننده ضعیف ایجاد کند. این کار با ساختن یک مدل از دادههای آموزشی، سپس ایجاد مدل دوم که سعی در تصحیح خطاهای مدل اول دارد، انجام میشود. مدلها اضافه میشوند تا زمانی که مجموعه آموزشی به طور کامل پیشبینی شود یا حداکثر تعداد مدل اضافه شود.

AdaBoost اولین الگوریتم بوستینگ واقعاً موفقی بود که برای طبقه بندی باینری توسعه یافت. این بهترین نقطه شروع برای درک تقویت است. روشهای تقویت مدرن مبتنی بر AdaBoost، به ویژه ماشینهای تقویت گرادیان تصادفی، ساخته شدهاند.
توضیح AdaBoost
AdaBoost با درختهای تصمیم کوتاه استفاده میشود. پس از ایجاد اولین درخت، عملکرد درخت در هر نمونه آموزشی برای وزن دادن به میزان توجه درخت بعدی استفاده می شود که ایجاد شده و باید به هر نمونه آموزشی توجه کند. به دادههای تمرینی که پیشبینی آنها سخت است، وزن بیشتری داده میشود، در حالی که به نمونههای آسان برای پیشبینی وزن کمتری داده میشود. مدلها بهطور متوالی یکی پس از دیگری ایجاد میشوند و هر کدام وزنهای مربوط به نمونههای آموزشی را بهروزرسانی میکنند که بر یادگیری انجامشده توسط درخت بعدی در دنباله تأثیر میگذارد. پس از ساخته شدن همه درختان، پیشبینیهایی برای دادههای جدید انجام میشود و عملکرد هر درخت بر اساس میزان دقت آن در دادههای آموزشی وزن میشود.
از آنجایی که توجه زیادی به اصلاح اشتباهات توسط الگوریتم میشود، مهم است که با حذف نقاط پرت، دادههای تمیز را داشته باشید.
از کدام یک از انواع الگوریتم های یادگیری ماشین باید استفاده کنیم؟
یک سوال معمولی که توسط فرد مبتدی هنگام مواجهه با طیف گستردهای از الگوریتم های یادگیری ماشین پرسیده میشود، این است که “از کدام الگوریتم یادگیری ماشین استفاده کنم؟” پاسخ به این سوال با توجه به عوامل بسیاری متفاوت است، از جمله:
- اندازه، کیفیت و ماهیت دادهها
- زمان محاسباتی موجود
- فوریت کار
- کاری که می خواهید با داده ها انجام دهید.
حتی یک دانشمند علوم داده با تجربه نمیتواند بگوید کدام الگوریتم، قبل از امتحان انواع الگوریتم های یادگیری ماشین، بهترین عملکرد را دارد. اگرچه بسیاری دیگر از الگوریتم های یادگیری ماشین وجود دارند، اما الگوریتمهایی که در این مقاله به آنها اشاره کردیم، محبوبترین آنها هستند. اگر در یادگیری ماشین مبتدی هستید، اینها نقطه شروع خوبی برای یادگیری خواهند بود.
خدمات یوآیدی
یوآیدی اولین ارائهدهنده وب سرویس احراز هویت بایومتریک در کشور، برای سهولت دسترسی و استفاده از احراز هویت دیجیتال وب سرویسهای زیر را توسعه داده است. با وب سرویسهای کسب و کارها میتوانند کاربران خود را با بالاترین دقت و درجه اطمینان احراز هویت کنند.
سوالات متداول
الگوریتمهای یادگیری ماشین روشهای نقشهبرداری مدل ریاضی هستند که برای یادگیری یا کشف الگوهای زیربنایی تعبیهشده در دادهها استفاده میشوند. یادگیری ماشین شامل گروهی از الگوریتمهای محاسباتی است که میتوانند با یادگیری از دادههای موجود (مجموعه آموزشی)، تشخیص، طبقهبندی و پیشبینی الگو را روی دادهها انجام دهند.
الگوریتمهای یادگیری ماشین معمولاً توسط دانشمندان کامپیوتر، دانشمندان علوم داده و محققانی با تخصص در ریاضیات، آمار و برنامهنویسی کامپیوتر توسعه مییابند.
یادگیری ماشین از دو نوع تکنیک استفاده میکند: یادگیری نظارت شده که مدلی را روی داده های ورودی و خروجی شناخته شده آموزش می دهد تا بتواند خروجی های آینده را پیش بینی کند و یادگیری بدون نظارت که الگوهای پنهان یا ساختارهای درونی را در داده های ورودی پیدا میکند.