

یادگیری ماشین یا ماشین لرنینگ چیست
یادگیری ماشین (Machine Learning) به زبان ساده، شاخهای از هوش مصنوعی است که به کامپیوترها اجازه میدهد از تجربیات و دادههای گذشته یاد بگیرند و عملکرد خود را در انجام وظایف مختلف به مرور زمان بهبود دهند. به عبارت دیگر، به جای این که برنامهنویس برای هر گام از فرایند کاری، یک الگوریتم بنویسد، سیستم با استفاده از دادههای موجود الگوها را تشخیص میدهد و بر اساس آن تصمیمگیری میکند. برای مثال، اگر به مدلی تصاویر مختلف گربه و سگ نشان دهیم، الگوریتم یادگیری ماشین با تحلیل ویژگیهای این تصاویر میتواند تفاوت میان گربه و سگ را یاد گرفته و تشخیص دهد چه تصویر جدیدی شامل گربه یا سگ است.
از نظر فنی، یادگیری ماشین شامل طراحی مدلها یا الگوریتمهایی است که میتوانند پارامترهای داخلی خود را بر اساس دادههای ورودی تنظیم کنند. این مدلها معمولا پارامترهایی دارند که در مرحله آموزش با دادهها تنظیم میشوند تا عملکرد دقیقتری داشته باشند. پس از آموزش، مدل نهایی میتواند بر اساس دادههای جدید، خروجی مناسب را تولید کند.
مقاله پیشنهادی: الگوریتم های یادگیری ماشین
یادگیری ماشین و علم داده (Data Science) ارتباط نزدیکی دارند اما مفاهیم متفاوتی هستند. به گفته شرکت فناوری چندملیتی آمریکایی IBM، «علم داده ساختاردهی به دادههای بزرگ را بر عهده دارد، در حالی که یادگیری ماشین روی یادگیری مستقیم از خود دادهها متمرکز است». در عمل، متخصصان علم داده ابتدا دادهها را جمعآوری، پاکسازی و آماده میکنند و با ابزارهای آماری و تصویری تحلیل میکنند، سپس تکنیکهای یادگیری ماشین روی همان دادهها اعمال میشود تا مدلهای پیشبینی یا طبقهبندی ساخته شود. میتوان گفت هر دو دانش در کنار هم قرار میگیرند: یادگیری ماشین بخشی از مجموعه ابزار هوش مصنوعی است که از نتایج علم داده بهره میبرد تا مسائل واقعی را حل کند. یادگیری ماشین به طور سنتی به عنوان زیرمجموعهای از هوش مصنوعی ai شناخته میشود و تمرکز آن بر توسعه الگوریتمهایی است که میتوانند از دادهها یاد بگیرند و پیشبینی یا تصمیمگیری کنند.
تاریخچه یادگیری ماشین

ریشههای نظری یادگیری ماشین به دهه ۱۹۴۰ بازمیگردد. در سال ۱۹۴۳، وارن مککالاک (Warren McCulloch) و والتر پیتس (Walter Pitts) نخستین مدل ریاضی یک نورون مصنوعی را معرفی کردند که مبنای شبکههای عصبی شد. سپس در ۱۹۴۹، دونالد هب (Donald Hebb) مفاهیم اولیه یادگیری عصبی را مطرح کرد.
اما نقطه عطف واقعی در دهه ۱۹۵۰ رخ داد: در سال ۱۹۵۲ آرتور ساموئل (Arthur Samuel) در آزمایشگاه IBM برنامهای برای بازی فکری «چکرز» توسعه داد و در همان سال اصطلاح «یادگیری ماشین» را ابداع کرد. در سال ۱۹۵۷ نیز فرانک روزنبلات (Frank Rosenblatt) به همراه دیگران «پرسپترون» را ساخت؛ یک شبکه عصبی تکلایه که برای تشخیص الگو طراحی شده بود. این پیشرفتها نویدبخش ورود جدی ML به دنیای محاسبات بود.
در دهه ۱۹۶۰ و ۱۹۷۰، پژوهشگران روی الگوریتمهای مختلف کار کردند. مثلاً در ۱۹۶۳ دونالد میچی (Donald Michie) با استفاده از ایده یادگیری تقویتی، ماشینی با مدلی ساده (جعبهها و مهرههای بازی) ساخت که میتوانست بازی دوز (تی-تیک-تو) را با آزمون و خطا یاد بگیرد. در ۱۹۶۷ نیز الگوریتم نزدیکترین همسایه (Nearest Neighbor) ابداع شد که بنیان بسیاری از کاربردهای دستهبندی و تشخیص الگو را گذاشت.
اما در اواخر دهه ۱۹۶۰ انتشار کتاب «پرسپترونها» توسط ماروین مینسکی (Marvin Minsky) و سیمور پاپرت (Seymour Papert) نشان داد برخی محدودیتهای ساختاری وجود دارد؛ این موضوع به رکود کوتاهی در تحقیق روی شبکههای عصبی منجر شد. با این حال در دهه ۱۹۷۰ تکنیک «پسانتشار» (Backpropagation) توسط محققین معرفی شد (بهویژه کار لینیناما در ۱۹۷۰) که بعدها زیربنای اصلی یادگیری عمیق شد.
همزمان پیشرفتهای سختافزاری و افزایش دادهها در دهه ۱۹۹۰ باعث شد یادگیری ماشین دوباره احیا شود. در این دوره تمرکز از روشهای اقتباسی به روشهای دادهمحور منتقل شد و روشهایی مانند ماشین بردار پشتیبان (SVM) و شبکههای عصبی بازگشتی محبوبیت یافت. این رشد شتاب ۱۹۹۰ بهخوبی با انفجار استفاده از اینترنت و دادههای دیجیتال همزمان بود: یادگیری ماشین در دهه ۱۹۹۰ به دلیل دسترسی وسیع به دادههای دیجیتال و اینترنت، رونق ویژهای یافت.
در دهههای بعد، شرکتها و دانشگاههای مطرح جهان به سرمایهگذاری جدی در این حوزه پرداختند. مثلاً در دهه ۲۰۰۰ سیستمهای قدرتمندی مانند Deep Blue در شطرنج و Watson در بازی اطلاعات عمومی (Jeopardy!) توسط IBM توسعه یافتند؛ Watson در سال ۲۰۱۱ قهرمان مسابقه Jeopardy را شکست داد و توانایی فوقالعاده ماشین لرنینگ در درک زبان طبیعی را به نمایش گذاشت. در دهه ۲۰۱۰، با قدرتنمایی یادگیری عمیق و شبکههای عصبی بزرگ، پیشرفتهای چشمگیری در تشخیص تصویر و پردازش زبان طبیعی حاصل شد؛ مثلاً در سال ۲۰۱۲ مدلی عمیق (شبکه عصبی کانولوشنی AlexNet) جایگاه نخست رقابت شناسایی تصاویر ImageNet را کسب کرد و نشان داد شبکههای عمیق قابلیتهایی فراتر از روشهای کلاسیک دارند.
امروزه یادگیری عمیق جزئی جداییناپذیر از صنایع مختلف است. در دهه ۲۰۲۰ فناوریهای مبتنی بر هوش مصنوعی مولد (Generative AI) نظیر GPT-3 و ChatGPT نیز ظهور کردند که بر پایه معماریهای پیشرفته یادگیری عمیق، پردازش زبان طبیعی را به سطح جدیدی بردند. در کل، دانشگاهها و شرکتهای پیشرو از MIT و استنفورد گرفته تا گوگل، مایکروسافت و فیسبوک، هر کدام نقش بزرگی در پیشبرد یادگیری ماشین ایفا کردهاند.
انواع روش های یادگیری ماشین

یادگیری ماشین بهطور کلی شامل سه دسته اصلی است:
۱. یادگیری نظارتشده (Supervised Learning)
در این روش، مدل با دادههای برچسبخورده آموزش میبیند تا خروجیهای آینده را پیشبینی کند. هر داده آموزشی شامل ورودی (ویژگیها) و خروجی متناظر (برچسب) است. مدل سعی میکند رابطه بین ورودی و خروجی را یاد بگیرد. بهعنوان مثال، مدلی را در نظر بگیرید که قیمت خانهها را پیشبینی میکند: این مدل با مجموعهای از مشخصات خانهها (متراژ، تعداد اتاق و…) و قیمت واقعی آنها آموزش داده میشود، سپس بر اساس پارامترهای یادگرفتهشده قیمت خانههای جدید را تخمین میزند. یا سیستم فیلترینگ اسپم در ایمیل را فرض کنید که با دادههای آموزش متشکل از ایمیلهای برچسبخورده بهعنوان «اسپم» یا «غیر اسپم» ساخته میشود؛ سپس هر ایمیل جدید را با استفاده از ویژگیهایش طبقهبندی میکند. به بیان دیگر، در یادگیری نظارتشده مدل از دانش گذشته (دادههای آموزشی) با برچسب مشخص استفاده میکند تا خروجی صحیح را برای دادههای جدید پیشبینی کند.
۲. یادگیری بدون نظارت (Unsupervised Learning)
در این رویکرد، دادههای آموزشی برچسب ندارند و مدل باید خودبهخود ساختار یا الگوهای پنهان در دادهها را کشف کند. هدف اصلی این است که گروهبندیها، همبستگیها یا نمایشهای فشرده از دادهها پیدا شود.
برای مثال، در بازاریابی اینترنتی ممکن است بخواهیم مشتریان را بر اساس رفتار خرید به گروههای متفاوت تقسیم کنیم؛ در اینجا الگوریتم بدون نظارت دستهبندی (خوشهبندی) میتواند مشتریانی با الگوهای خرید مشابه را در یک گروه قرار دهد. یا در کاهش ابعاد، الگوریتمهایی مانند PCA ساختاری کمبعد برای دادهها مییابند. در این روش مدل هیچگونه برچسب ۰ یا ۱ (مانند اسپم/غیر اسپم) ندارد و تنها بر رفتار دادهها تکیه میکند تا بفهمد مثالها چگونه بهطور طبیعی دستهبندی میشوند. بهعنوان مثال ساده، فرض کنید مجموعهای از تصاویر بدون برچسب دارید و الگوریتم خوشهبندی تصاویر مشابه را کنار هم قرار میدهد؛ کاربر میتواند معنای کلی هر خوشه (مثلاً «گربهها»، «سگها» و…) را بهصورت دستی تشخیص دهد. در کل، یادگیری بدون نظارت کمک میکند تا با تجزیه و تحلیل دادههای خام بدون راهنمایی آشکار، ساختار و الگوهای مهم را بیابیم.
۳. یادگیری تقویتی (Reinforcement Learning)
در یادگیری تقویتی، مدل یا عامل (Agent) از طریق آزمون و خطا در تعامل با یک محیط یاد میگیرد که چه اقداماتی انجام دهد تا پاداش کل (Reward) را بیشینه کند و به حداکثر برساند. روند کار به این صورت است که عامل، در هر مرحله وضعیت (State) فعلی را دریافت میکند، عملی را انجام میدهد، سپس بر اساس نتیجه اقدام، یک پاداش مثبت یا منفی میگیرد و وارد وضعیت جدید میشود. الگوریتم یادگیری تقویتی سعی میکند پیامدهای آتی اعمال خود را پیشبینی کند و از پاداشها استفاده میکند تا سیاست بهینه یادگیری را بیابد. برای مثال، در یک بازی شطرنج، عامل هوشمند با انجام حرکات مختلف و دریافت پاداش (برد یا باخت) میآموزد استراتژیهایی را اتخاذ کند که احتمال برد را افزایش دهد.
یکی از مهمترین دستاوردهای یادگیری تقویتی (Reinforcement Learning)، توسعهی مدل AlphaGo توسط شرکت DeepMind در سال ۲۰۱۶ بود. این مدل توانست برای اولین بار قهرمان جهان در بازی Go را شکست دهد؛ بازیای که به دلیل پیچیدگی بسیار بالا و تعداد حالتهای ممکن، مدتها بهعنوان یکی از بزرگترین چالشهای هوش مصنوعی شناخته میشد. AlphaGo با یادگیری از میلیونها بازی و همچنین بازیکردن با خودش، توانست استراتژیهایی پیشبینیناپذیر و بسیار مؤثر ایجاد کند که حتی برای بازیکنان حرفهای شگفتانگیز بود.
به بیان ساده، یادگیری تقویتی اجازه میدهد مدل بر اساس دریافت بازخورد (پاداش یا جریمه) از محیط رفتار خود را بهبود بخشد این روش بهویژه در مسائل تصمیمگیری پیاپی مانند بازیهای رایانهای، کنترل رباتها و سیستمهای دینامیکی کاربرد فراوان دارد.
مقاله پیشنهادی: یادگیری تقویتی چیست؟ الگوریتم های یادگیری تقویتی
مراحل پیادهسازی یک پروژه یادگیری ماشین
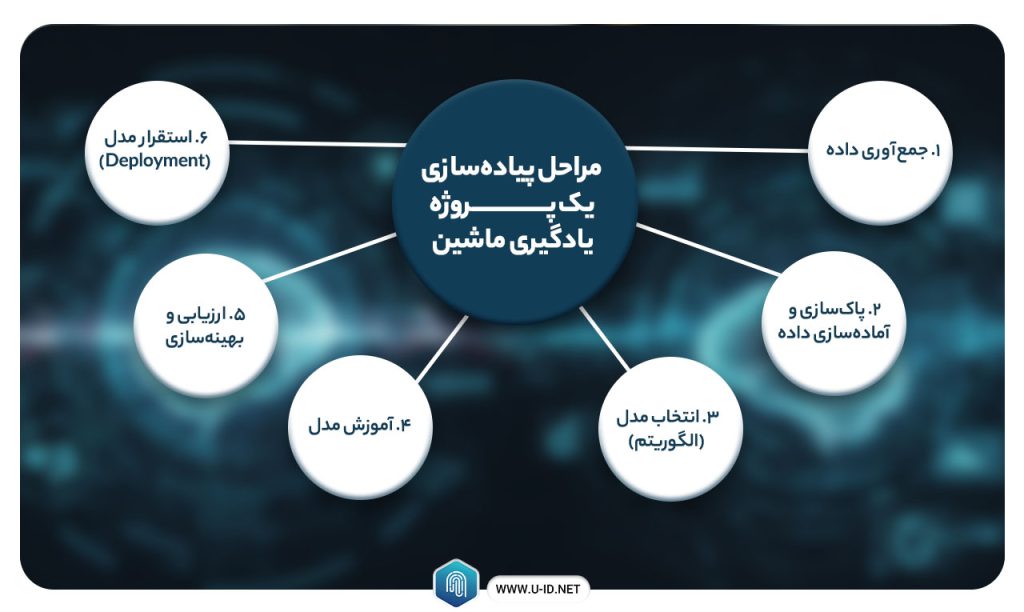
پیادهسازی یک پروژه یادگیری ماشین معمولاً مراحل زیر را در بر میگیرد:
۱. جمعآوری داده: در ابتدا، دادههای مرتبط با مسأله جمعآوری میشوند. این دادهها ممکن است از منابع مختلف (پایگاه دادهها، سنسورها، APIها و غیره) حاصل شوند. کیفیت و کمیت دادهها بسیار مهم است. پژوهشها نشان داده آمادهسازی دادهها میتواند تا ۸۰٪ از زمان یک پروژه ماشین لرنینگ را به خود اختصاص دهد، زیرا معمولاً دادههای اولیه دارای خطا، نواقص یا دادههای مفقود هستند.
۲. پاکسازی و آمادهسازی داده: پس از جمعآوری، دادهها باید پاکسازی و در قالب مناسب آماده شوند. این مرحله شامل حذف یا جایگزینی دادههای گمشده، حذف نویز و دادههای پرت، نرمالسازی یا مقیاسدهی ویژگیها و تبدیل ویژگیهای غیرعددی به قالب عددی است. در بسیاری از پروژهها، این گام بحرانیتر از خود الگوریتم یادگیری است؛ زیرا وجود دادهٔ باکیفیت تضمین میکند مدل بتواند مفید باشد.
۳. انتخاب مدل (الگوریتم): در این مرحله باید الگوریتم مناسب برای مسأله انتخاب شود. بهعنوان مثال، برای مسائل پیشبینی مقداری (Regression) میتوان از رگرسیون خطی یا درخت تصمیم بهره برد؛ برای مسائل طبقهبندی، الگوریتمهایی مانند درخت تصمیم، جنگل تصادفی، ماشین بردار پشتیبان یا شبکههای عصبی کاربرد دارد. انتخاب الگوریتم معمولاً بر اساس ماهیت دادهها و نوع خروجی (عدد یا دسته) صورت میگیرد. نکته مهم این است که باید از میان الگوریتم های یادگیری ماشین رایج، گزینهای را برگزید که احتمال بالاتری برای یادگیری الگوها در دادهها داشته باشد.
۴. آموزش مدل: دادههای پاکسازیشده به دو مجموعه «آموزش» و «آزمون» تقسیم میشوند. مدل یادگیری ماشین روی مجموعه آموزش «تمرین» میکند تا پارامترهایش (مانند وزنها در شبکه عصبی) را تنظیم کند. معمولاً فرآیند آموزش شامل تکرار (Epoch) است تا ضرر مدل در پیشبینی به حداقل برسد. در این گام مدل بهطور خودکار ویژگیهای دادهها را بررسی و بهترین سازگاری ممکن را میآموزد. مثلاً در رگرسیون خطی، ضرایب مدل طوری تنظیم میشوند که خطا میان مقادیر پیشبینیشده و واقعی کمینه شود.
۵. ارزیابی و بهینهسازی: پس از آموزش اولیه، مدل روی مجموعه آزمون ارزیابی میشود تا عملکرد آن اندازهگیری شود. معیارهایی مانند دقت (Accuracy)، میانگین مربعات خطا (MSE)، درستی و جامعیت (Precision/Recall) و … با توجه به نوع مسأله محاسبه میشوند. تکنیکهایی مانند اعتبارسنجی متقابل (Cross-Validation) نیز به کار میروند تا اطمینان حاصل شود مدل روی دادههای جدید هم خوب عمل میکند و بیشبرازش (Overfitting) ندارد. با نتایج ارزیابی، ممکن است پارامترهای مدل (هیپرپارامترها) تنظیم شود و یا الگوریتم بهینهتر انتخاب شود تا دقت مدل افزایش یابد.
۶. استقرار مدل (Deployment): پس از تأیید کیفیت مدل، آن را در محیط عملیاتی مستقر میکنند تا در دنیای واقعی قابل استفاده باشد. مثلاً یک مدل تشخیص بیماری ممکن است به سیستم اطلاعات بیمارستان متصل شود، یا یک مدل پیشبینی فروش در سیستم آنلاین فروشگاه پیاده شود. مانند آنچه در مقالهای آمده، گام استقرار شامل در دسترس قرار دادن مدل برای کاربران است: یا مدل را در یک نرمافزار موجود ادغام میکنند و یا بهصورت یک سرویس تحت وب راهاندازی میکنند که درخواستهای جدید را دریافت و پاسخ تولید میکند. استقرار موفق همچنین نیازمند نظارت مداوم است تا اطمینان حاصل شود مدل همچنان در شرایط جدید عملکرد خوبی دارد و در صورت لزوم بازآموزی شود.
کاربردهای یادگیری ماشین در صنایع مختلف

یادگیری ماشین در بسیاری از صنایع و زمینهها کاربرد دارد. در زیر چند نمونه مطرح شدهاند:
۱. پزشکی (تشخیص بیماری)
ماشین لرنینگ در پزشکی با بررسی دادههای بیمار (تصاویر رادیولوژی، علائم حیاتی، آزمایشهای بالینی و…) میتواند به تشخیص بیماری کمک کند. برای مثال، مدلهای یادگیری عمیق قادرند تومورهای سرطانی را از روی تصاویر پزشکی شناسایی کنند و بیماریهای مختلف را پیشبینی کنند. طبق آمار، بازار هوش مصنوعی در مراقبتهای بهداشتی از ۱۱ میلیارد دلار در ۲۰۲۱ به حدود ۱۸۸ میلیارد دلار در ۲۰۳۰ خواهد رسید، که نشاندهنده نفوذ گسترده ماشین لرنینگ در تشخیص، درمانهای شخصیسازیشده و پژوهشهای بالینی است.
۲. بانکداری و فینتک (کشف تقلب و مدیریت مالی)
در بخش مالی، الگوریتمهای یادگیری ماشین برای کشف تقلب، شناسایی تراکنشهای مشکوک و پیشبینی ریسک اعتباری استفاده میشوند. برای مثال، سیستمهای ماشین لرنینگ با تحلیل الگوهای تراکنش کارت اعتباری میتوانند تراکنشهای غیرعادی را تشخیص دهند. همچنین در برنامهریزی مالی شخصی و تخصیص دارایی، یادگیری ماشین پیشنهادهای هوشمند میدهد. به گفته وبسایت intuition.com، حوزههایی مانند برنامهریزی مالی شخصی، تشخیص تقلب بانکی و مبارزه با پولشویی جزو ظرفیتهای اصلی ماشین لرنینگ در بانکداری هستند. نکته جالب توجه این است که حدود ۸۰٪ بانکها از مزایای ماشین لرنینگ آگاه هستند. برای مثال برای احراز هویت کاربران در خدمات بانکی امروزی از سرویسهای تخصصی استفاده میشود؛ بهعنوان نمونه برخی بانکها همراه با سیستمهای پیشرفته ماشین لرنینگ از سرویسهای تشخیص هویت مثل وب سرویس احراز هویت بهره میبرند تا از دسترسی غیرمجاز جلوگیری کنند.
یوآیدی در ایران این خدمات را به کسبوکارها، از جمله بانکها و شرکتهای فعال در حوزه فینتک ارائه میدهد.
برای دریافت وب سرویس های احراز هویت در کسبوکار خود، از طریق فرم با کارشناسان یوآیدی ارتباط بگیرید.
۳. فروشگاههای آنلاین و تجارت الکترونیک
در زمینه فروش اینترنتی، پیشنهاد خودکار محصول به مشتری بر اساس سابقه خرید و مرور او یک کاربرد شناختهشده ماشین لرنینگ است. برای نمونه، نتفلیکس (که سرویس ویدئوی آنلاین است) حدود ۷۵٪ از پیشنهادهای نمایش دادهشده را با استفاده از الگوریتمهای یادگیری ماشین تولید میکند. همچنین ML میتواند موتور جستجوی داخلی فروشگاه را هوشمندتر کند و نرخ تبدیل فروشگاه را افزایش دهد؛ طبق اعلام وبسایت بیگکامرس، ماشین لرنینگ با بهبود جستجو و تولید «پیشنهادهای محصول» آگاهانه، میتواند نرخ تبدیل مشتری را بهطور محسوسی بالا ببرد. بهطور خلاصه، هر پلتفرم تجارت الکترونیکی که میخواهد محصولات مرتبط را به کاربر پیشنهاد دهد، به یادگیری ماشین نیاز دارد.
۴. خودروهای خودران
در وسایل نقلیه خودران و نیمهخودران، یادگیری ماشین نقش کلیدی دارد. خودروها به کمک دادههای حسگرها (دوربینها، لیدار، رادار و…) و مدلهای ماشین لرنینگ میتوانند مسیرها، علائم راهنمایی، موانع و وضعیت سایر خودروها را تشخیص دهند و تصمیمات رانندگی بگیرند. به گزارش دانشگاه بوستون، «خودروهای خودران توسط الگوریتمهای یادگیری ماشین تغذیه میشوند که به مقادیر زیادی از دادههای رانندگی نیاز دارند تا با اطمینان عمل کنند». به این ترتیب، سیستمهایی همچون تشخیص خط جاده، اجتناب از برخورد و پیشبینی رفتار رانندگان دیگر توسط مدلهای ماشین لرنینگ مدیریت میشود. در خودروهای الکتریکی پیشرفته مانند تسلا یا پروژه Waymo گوگل از این فناوریها استفاده شده است و به مرور زمان عملکرد خود را بهبود میدهند.
مزایا و معایب یادگیری ماشین

یادگیری ماشین مانند هر فناوری دیگری دارای مزایا و معایب خاص خود است. برخی از مهمترین آنها عبارتاند از:
مزایا:
اتوماسیون و کارایی بیشتر: یادگیری ماشین میتواند کارهای تکراری و پردازش حجم زیادی از دادهها را به صورت خودکار انجام دهد و در نتیجه در زمان و هزینه صرفهجویی کند.
دقت و پیشبینی بالا: مدلهای یادگیری ماشین با تحلیل دادههای گذشته قادر به تشخیص الگوها و روندها هستند. این امر منجر به پیشبینیهای دقیقتر و تصمیمهای آگاهانهتر میشود. برای مثال، تشخیص بهموقع بیماری یا جلوگیری از تقلب مالی از نتایج مثبت این دقت هستند.
انعطافپذیری: یادگیری ماشین در حوزههای گوناگونی کاربرد دارد؛ از تشخیص تصویر و پردازش گفتار گرفته تا تحلیل متون و بازیهای رایانهای. این انعطافپذیری باعث شده در صنایع مختلفی مانند فناوری، پزشکی، مالی و خودروسازی مورد استفاده قرار گیرد.
یادگیری و بهبود مستمر: سیستمهای یادگیری ماشین میتوانند با اضافه شدن دادههای جدید، عملکرد خود را به مرور زمان بهتر کنند. به عبارت دیگر، این سیستمها با کسب تجربه و داده بیشتر به مرور هوشمندتر میشوند و میتوانند خود را با شرایط جدید سازگار کنند.
معایب:
نیاز به داده و منابع محاسباتی زیاد: آموزش مدلهای یادگیری ماشین به مقدار زیادی داده آموزشی و توان محاسباتی بالا نیاز دارد. جمعآوری و آمادهسازی این دادهها زمانبر و پرهزینه است و برای پردازش دادههای بزرگ نیز به سختافزار قدرتمند (مانند GPU) نیاز دارد.
عدم شفافیت (جعبه سیاه): بسیاری از مدلهای یادگیری ماشین، بهویژه مدلهای پیچیده مانند شبکههای عصبی عمیق، مانند یک جعبه سیاه عمل میکنند؛ یعنی نحوه تصمیمگیری دقیق آنها برای انسان مشخص نیست. این موضوع میتواند در برخی کاربردها (مثلاً پزشکی یا مالی) نگرانیهایی در مورد توضیحپذیری نتایج ایجاد کند.
محدودیتهای مقیاسپذیری: برخی الگوریتمهای یادگیری ماشین در مقیاس بسیار بزرگ (مثلاً میلیاردها داده) کارایی کمتری دارند یا نیاز به تکنیکهای خاص دارند.
سوگیری و عدم تعمیم: اگر دادههای آموزشی دارای سوگیری (Bias) باشند، مدل نیز چنین سوگیریهایی را یاد میگیرد و تصمیمات نادرستی اتخاذ میکند. همچنین ممکن است مدل آموزشدیده در مواجهه با دادههای جدید (خارج از نمونههای آموزشی) دچار مشکل شود.
مسائل امنیتی و حریم خصوصی: مدلهای یادگیری ماشین ممکن است نسبت به حملات مخرب (Adversarial Attacks) آسیبپذیر باشند؛ به این معنی که با تغییرات ظریف در دادههای ورودی میتوان مدل را گمراه کرد. همچنین حریم خصوصی دادهها هنگام جمعآوری و آموزش مدل اهمیت دارد و باید مورد توجه قرار گیرد.
تأثیر بر اشتغال: خودکارسازی وظایف با یادگیری ماشین ممکن است در برخی شغلهای تکراری باعث کاهش نیاز به نیروی کار انسانی شود. اما در عین حال تقاضا برای مهارتهای جدید مانند توسعه دهندگان هوش مصنوعی افزایش مییابد.
تفاوت یادگیری ماشین و یادگیری عمیق
یادگیری عمیق deep learning شاخهای از یادگیری ماشین است که به آموزش شبکههای عصبی پیچیده و چندلایه میپردازد. مهمترین تفاوت بین یادگیری ماشین سنتی و یادگیری عمیق به طراحی مدل و نیازهای دادهای برمیگردد.
به گفته IBM، «یادگیری عمیق (Deep Learning) در واقع زیرمجموعهای از یادگیری ماشین است که بر شبکههای عصبی با لایههای متعدد تمرکز دارد. یادگیری ماشین، یادگیری عمیق و شبکههای عصبی همه زیرمجموعههای هوش مصنوعی هستند؛ اما شبکههای عصبی خود زیرمجموعه یادگیری ماشین هستند و یادگیری عمیق زیرمجموعه شبکههای عصبی است».
تفاوت اصلی این دو در نحوه یادگیری دادهها است: در یادگیری عمیق، الگوریتمها قادرند مستقیماً از دادههای خام (مانند تصاویر، صدا یا متن) بدون نیاز به طراحی ویژگیهای دستی استفاده کنند. در واقع شبکههای عمیق لایههای پنهان زیادی دارند و بهطور خودکار ویژگیهای مختلف را استخراج میکنند. این امر دخالت انسان را در فرایند طراحی ویژگی کاهش میدهد و امکان استفاده از حجم بالایی از دادهها را فراهم میکند. از سوی دیگر، یادگیری ماشین «غیرعمیق» (مانند مدلهای رگرسیون، درخت تصمیم یا SVM) معمولاً نیاز به دستی تعیین کردن ویژگیها توسط متخصص دارد تا بتواند ورودیها را طبقهبندی کند. در عمل، اگر دادهها ساختاریافته نباشند و حجم زیادی داشته باشند، یادگیری عمیق نتایج بهتری میدهد؛ اما برای مسائل سبکتر و دادههای اندازهتر، روشهای کلاسیک ماشین لرنینگ اغلب سادهتر و شفافتر هستند.
برای مطالعه مفصل تفاوت بین این دو حوزه، مقاله تفاوت یادگیری عمیق و یادگیری ماشین را بخوانید.
اهمیت یادگیری ماشین در آینده مشاغل و صنایع
یادگیری ماشین بهطور گستردهای به عنوان یکی از مهارتهای کلیدی آینده در نظر گرفته میشود. طبق نظرسنجی کمپانی Deloitte، اکنون حدود ۶۷٪ شرکتها از تکنیکهای ماشین لرنینگ بهره میبرند و در واقع ۹۷٪ شرکتها استفاده از آن را در برنامههای کوتاهمدت یا میانمدت در نظر دارند. رشد سریع بازار نیز نشاندهنده استقبال صنعت است: انتظار میرود بازار ماشین لرنینگ تا سال ۲۰۲۹ به حدود ۲۱۰ میلیارد دلار برسد و مجموع بازار هوش مصنوعی (که شامل ماشین لرنینگ میشود) تا سال ۲۰۳۰ به حدود ۱.۶ تریلیون دلار افزایش یابد.
این روند موجب شده است فرصتهای شغلی فراوانی در حوزه ماشین لرنینگ و هوش مصنوعی ایجاد شود. برای نمونه، اداره آمار کار آمریکا پیشبینی کرده مشاغل مرتبط با هوش مصنوعی (که شامل مهندسان یادگیری ماشین نیز هست) از سال ۲۰۲۱ تا ۲۰۳۱ حدود ۲۱٪ رشد خواهند داشت؛ یعنی چندین برابر نرخ رشد شغلی متوسط. به عبارت دیگر، در صنایع مختلف آینده – از بهداشت و درمان و بانکداری تا تجارت الکترونیک و خودروسازی – توانمندی در یادگیری ماشین بهعنوان یک مهارت ضروری شناخته میشود. شرکتها در سرتاسر جهان با سرمایهگذاری در تحقیق و توسعه ماشین لرنینگ و محصولات مبتنی بر آن سعی میکنند در رقابت پیشتاز بمانند، و دانشگاهها نیز دانشجویان را برای این بازار پرتقاضا آماده میکنند.
سوالات متداول
مدلهای یادگیری ماشین با دریافت حجم زیادی از دادهها، الگوها را یاد میگیرند و سپس از آن الگوها برای پیشبینی یا تصمیمگیری روی دادههای جدید استفاده میکنند.
پایتون بهدلیل سادگی و داشتن کتابخانههای قوی پرکاربردترین زبان در ماشین لرنینگ است. زبانهایی مثل R، جاوا و ++C هم در برخی حوزهها استفاده میشوند.
هوش مصنوعی حوزهای گستردهتر است و شامل یادگیری ماشین هم میشود. یادگیری ماشین تمرکز خاصی روی یادگیری از دادهها دارد.
بله، ابزارهای گرافیکی و سرویسهای بدون کدنویسی وجود دارند، اما برای پیشرفت واقعی، یادگیری برنامهنویسی بسیار مفید و ضروری است.







4 دیدگاه دربارهٔ «ماشین لرنینگ چیست؟ انواع، کاربردها و مراحل یادگیری ماشین»
من فرق هوش مصنوعی رو با یادگیری ماشین نمیفهمم :-(((
سلام سامان عزیز
مقاله “تفاوت یادگیری عمیق و یادگیری ماشین و ارتباط آنها با هوش مصنوعی” رو مطالعه بفرمایید تا با تفاوتهاشون بیشتر آشنا شید.
سلام. آموزش یادگیری ماشین با پایتون رو از کجا تهیه کنم بهتره؟
سلام نیمای عزیز
در این خصوص باید جستجوی کامل انجام بدید و نظرات متخصصان رو بخونید.