

شبکههای عصبی (ANNها) ابزاری قدرتمند برای یادگیری ماشین هستند که در طیف گستردهای از برنامهها کاربرد دارند. این شبکهها به طور مداوم در حال تکامل و پیشرفت هستند و احتمالاً در سالهای آینده نقش مهمتری در یادگیری ماشین و هوش مصنوعی ایفا خواهند کرد. نقش اصلی شبکه عصبی در یادگیری ماشینی، یادگیری از دادههای پیچیده و چندبعدی (یادگیری عمیق)، تشخیص الگو، پیشبینی مقادیر آینده بر اساس دادههای گذشته و حال، طبقهبندی دادهها و کاهش ابعاد دادهها است. در این مقاله از سامانه احراز هویت یوآیدی همراه ما باشید تا به جزئیات بیشتر در مورد شبکه عصبی و کاربرد آن و همچنین تفاوت شبکه عصبی و یادگیری ماشین بپردازیم.
شبکه عصبی چیست؟
به زبان ساده، شبکه عصبی (Neural Network) شبکه عصبی برنامهای است که برای تقلید از عملکرد مغز انسان طراحی شده است. به بیان دیگر، شبکه عصبی روشی در هوش مصنوعی است که به کامپیوترها می آموزد تا دادهها را به روشی پردازش کنند که از مغز انسان الهام گرفته شده است. در واقع، شبکه عصبی یک نوع فرآیند یادگیری ماشینی است که یادگیری عمیق نامیده میشود و از گرهها یا نورونهای به هم پیوسته در ساختار لایهای شبیه مغز انسان استفاده میکند. این سیستم، یک سیستم تطبیقی ایجاد میکند که کامپیوترها برای یادگیری از اشتباهات خود و بهبود مستمر استفاده می کنند. بنابراین، شبکههای عصبی مصنوعی سعی میکنند مسائل پیچیدهای مانند خلاصهسازی اسناد یا تشخیص چهره را با دقت بیشتری حل کنند.
شبکههای عصبی برای یادگیری و بهبود دقت خود در طول زمان به دادههای آموزشی متکی هستند. این شبکهها با دفت بالای خود، ابزار قدرتمندی در علوم کامپیوتر و هوش مصنوعی ai محسوب میشوند که به ما این امکان را میدهند تا دادهها را با سرعت بالا طبقهبندی و خوشهبندی کنیم. یکی از شناخته شدهترین نمونههای شبکه عصبی، الگوریتم جستجوی گوگل است.
شبکههای عصبی، گاهی اوقات شبکههای عصبی مصنوعی (ANN) یا شبکههای عصبی شبیهسازی شده (SNN) نیز نامیده می شوند. آنها زیرمجموعهای از یادگیری ماشینی هستند و در قلب مدلهای یادگیری عمیق قرار دارند.
کاربرد شبکه عصبی
شبکههای عصبی کاربردهای گستردهای در حوزههای مختلف دارند، از جمله:
- تشخیص اشیا، چهرهها و درک زبان گفتاری در برنامههایی مانند خودروهای خودران و دستیارهای صوتی.
- تحلیل و پردازش زبان انسانی برای انجام کارهایی مانند تحلیل احساسات، چتباتها، ترجمه زبان و تولید متن.
- تشخیص بیماریها از تصاویر پزشکی، پیشبینی نتایج درمان بیماران و کشف داروهای جدید.
- پیشبینی قیمت سهام، ارزیابی ریسک اعتباری، شناسایی تقلب و معاملات الگوریتمی.
- شخصیسازی محتوا و پیشنهادها در تجارت الکترونیک، پلتفرمهای استریم و شبکههای اجتماعی.
- تقویت رباتیک و وسایل نقلیه خودران با پردازش دادههای حسگرها و تصمیمگیری آنی.
- بهبود هوش مصنوعی در بازیها، تولید گرافیکهای واقعی و ایجاد محیطهای مجازی جذاب.
- نظارت و بهینهسازی فرایندهای تولید، نگهداری پیشبینانه و کنترل کیفیت.
- تحلیل مجموعه دادههای پیچیده، شبیهسازی پدیدههای علمی و کمک به پژوهش در رشتههای مختلف.
- تولید موسیقی، هنر و محتوای خلاقانه دیگر.
چرا شبکه عصبی در یادگیری ماشینی اهمیت زیادی دارد؟
شبکههای عصبی ابزاری قوی هستند که کسب و کارها از آن برای حل مشکلات پیچیده تجاری استفاده میکنند. شرکتها از این شکل شبکه برای شناسایی الگوها و پیشبینی رویدادهای نادر مانند کشف تقلب و کلاهبرداری اینترنتی استفاده میکنند.
این شبکهها قادر به ایجاد رابطه بین ورودیها و خروجیهای غیر خطی و پیچیده هستند. همین امر آنها را برای پروژههایی که برای دستیابی به موفقیت نیاز به تصمیم گیری مبتنی بر داده دارند، به گزینهای عالی تبدیل میکند. شبکههای عصبی همچنین در زمینههای زیر کاربردی و مهم هستند:
- کنترل کیفیت
- تشخیص صدا یا پردازش زبان طبیعی
- مراقبتهای بهداشتی برای تشخیص بیماری
- بازاریابی هدفمند
نقش شبکه عصبی در یادگیری ماشین
شبکههای عصبی و یادگیری ماشین دو تکنولوژی جدا از هم نیستند؛ بلکه شبکههای عصبی جزء جداییناپذیر از یادگیری ماشین به عنوان یک علم به شمار میروند.
اهمیت بالای شبکههای عصبی در هوش مصنوعی و یادگیری ماشین مدرن، به طور خاص به خاطر چشمانداز دادههای امروزی است:
- بسترهای داده بزرگ که شامل محیطهای ابری ترکیبی با کارایی بالا و تحلیل دادههای بزرگ میشود، حجم عظیمی از داده را که برای آموزش شبکههای عصبی پیچیده مورد نیاز است، فراهم میکنند. قبل از این فناوریها، دستیابی به انواع و حجم مناسب داده دشوار بود. این چالشها، امکانات هوش مصنوعی را با مشکل مواجه میکرد. با این حال، بسترهای داده مدرن، محیطی را به وجود آوردند که شبکههای عصبی میتوانستند روی مجموعه دادههای عظیم کار کنند و استراتژیها و عملیات پیچیده را بیاموزند.
- شتاب سختافزاری از طریق فناوریهایی مانند واحدهای پردازش گرافیک (GPU) تخصصی و حافظه غیرفرار پرسرعت (NVMe) باعث شده است که رایانش ابری با کارایی بالا به واقعیت تبدیل شود. در پی آن، بسترهای یادگیری ماشین توزیعشده و مقیاسپذیر برای سازمانها و پژوهشگران اختصاصی به راحتی قابل دسترس شدهاند.
این دو واقعیت، فرصتی واقعی را برای شبکههای عصبی و دیپ لرنینگ (یادگیری عمیق) ایجاد کردهاند. در حقیقت، برخی از مهمترین انتقادها به یادگیری عمیق، هزینههای گزاف ذخیرهسازی و توان محاسباتی بود. این هزینهها توسط بسترهای ابری رایانش با کارایی بالا برطرف شده است.
با وجود این، برخی انتقادات به یادگیری عمیق و شبکههای عصبی همچنان وجود دارد. این انتقادات شامل این موارد است که شبکههای عصبی ممکن است تنها پیشرفتهای سطحی را در سیستمهای پیچیدهای ارائه دهند که به نظر درک محدود انسان نیز به همان اندازه پیچیده است. علاوه بر این، نقد دیگری وجود دارد که نشان میدهد شبکههای عصبی میتوانند روابط پیچیده ورودیها و خروجیها (همبستگیها) را بدون درک واقعی علیت بیاموزند.
این انتقادات به معنای رد فوری این فناوری نیست، بلکه بیشتر به قاببندی پتانسیل آن، به ویژه در رابطه با بحثهای گستردهتر در مورد چگونگی رویکرد سیستمهای یادگیری ماشین به هوشمندی اشاره دارد.
با این حال، سیستمهای یادگیری ماشین با شبکههای عصبی پیشرفتهای قابل توجهی در زمینههای خاصی از جمله مدلسازی آماری، مدلسازی مالی و بیمهای، بهینهسازی و کنترل تولید و تعاملات محدود انسانی از طریق چتباتها داشتهاند.
۸ مورد از مهمترین کاربردهای شبکه عصبی در صنایع مختلف
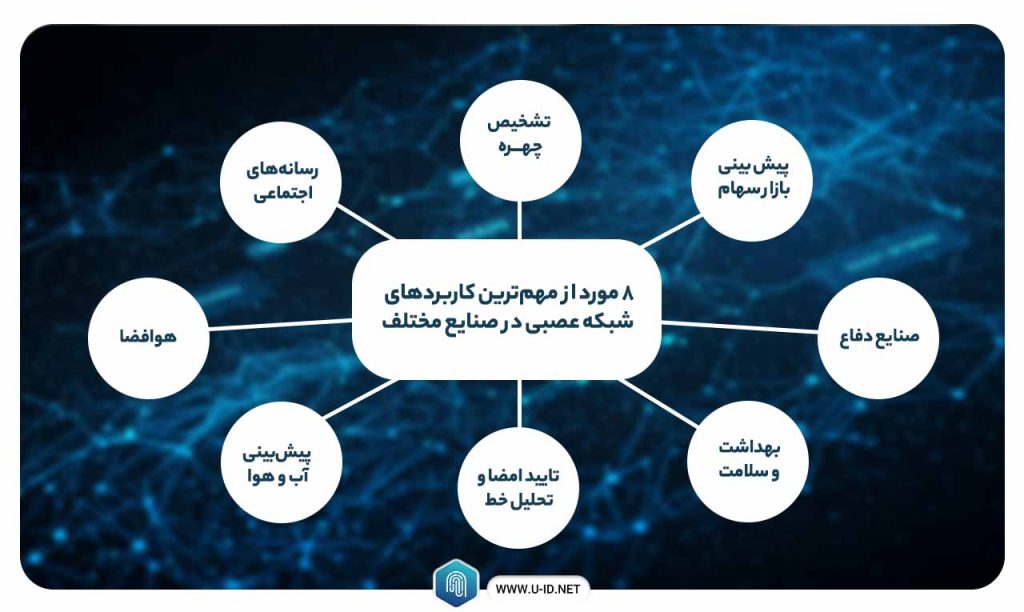
۱- تشخیص چهره
سیستمهای تشخیص چهره به عنوان ابزارهای قدرتمندی برای نظارت مورد استفاده قرار میگیرند. این سیستمها با مطابقت دادن چهره فرد با تصاویر دیجیتالی موجود در پایگاه داده خود، به شناسایی افراد میپردازند. از این سیستمها در ادارات برای کنترل ورود و خروج افراد استفاده میشود. بدین صورت که با احراز هویت فرد از طریق چهره و تطابق آن با لیست شناسههای موجود در پایگاه داده، مجوز ورود صادر میشود.
مقاله پیشنهادی: فناوری تطبیق یا تشخیص چهره یوآیدی
شبکههای عصبی کانولوشنال (CNN) برای تشخیص چهره و پردازش تصویر به کار گرفته میشوند. برای آموزش یک شبکه عصبی، تعداد زیادی از تصاویر به پایگاه داده وارد میشوند. این تصاویر جمعآوری شده برای آموزش شبکه پردازش و آمادهسازی میشوند.
لایههای نمونهگیری در CNN برای ارزیابی صحیح مدل به کار میروند. در نهایت، مدلها برای دستیابی به نتایج دقیق در تشخیص چهره بهینه میشوند.
۲- پیش بینی بازار سهام
سرمایهگذاری همواره با ریسکهای بازار همراه است. پیشبینی تغییرات آتی در بازار سهام که نوسانات زیادی دارد، تا چند وقت پیش تقریباً غیرممکن به نظر میرسید. پیش از ظهور شبکههای عصبی، تشخیص فازهای گاوی (صعودی) و خرسی (نزولی) که دائماً در حال تغییر هستند، غیرقابل پیشبینی بود. اما چه چیزی باعث این تغییر شد؟ مسلماً شبکههای عصبی!
برای پیشبینی موفق سهام در زمان واقعی، از یک مدل پرسپترون چندلایهٔ(MLP) که نوعی الگوریتم هوش مصنوعی پیشرو است، استفاده میشود.MLP از لایههای متعددی از گره تشکیل شده است که هر لایه به طور کامل به لایهٔ بعدی متصل است. برای ساخت مدل MLP، عملکرد گذشتهٔ سهام، بازده سالانه و نسبتهای سود ناخالص در نظر گرفته میشوند.
۳- رسانههای اجتماعی
شاید این موضوع کمی کلیشهای به نظر برسد، اما رسانههای اجتماعی مسیر عادی و کسالتبار زندگی را تغییر دادهاند. شبکه عصبی برای مطالعه رفتار کاربران شبکههای اجتماعی به کار گرفته میشود. دادههای به اشتراک گذاشته شده روزانه از طریق مکالمات و فعالیتهای مجازی جمعآوری و برای تحلیل رقابتی مورد بررسی قرار میگیرند.
شبکههای عصبی رفتار کاربران شبکههای اجتماعی را شبیهسازی میکنند. پس از تحلیل رفتارهای افراد از طریق شبکههای اجتماعی، میتوان دادهها را به عادات خرید افراد مرتبط کرد. برای استخراج دادهها از برنامههای رسانههای اجتماعی از چندلایهٔ پرسپترون شبکه عصبی مصنوعی (MLP ANN) استفاده میشود.
مدل MLP با استفاده از روشهای آموزشی مختلفی مانند خطای مطلق میانگین (MAE)، جذر میانگین مربعات خطا (RMSE) و میانگین مربعات خطا (MSE) به پیشبینی روندهای رسانههای اجتماعی میپردازد. MLP عوامل مختلفی مانند صفحات مورد علاقه کاربر در اینستاگرام، موارد ذخیرهشده و غیره را در نظر میگیرد. این عوامل به عنوان ورودی و دیتا برای آموزش مدل MLP در نظر گرفته میشوند.
با توجه به پویایی و دائماً در حال تغییر بودن برنامههای رسانههای اجتماعی، شبکههای عصبی قطعاً میتوانند به عنوان بهترین مدل مناسب برای تحلیل دادههای کاربر عمل کنند.
۴- هوافضا
مهندسی هوافضا اصطلاحی گسترده است که شامل توسعه فضاپیما و هواپیما میشود. تشخیص عیب، خلبان خودکار با کارایی بالا، ایمنسازی سامانههای کنترل هواپیما و مدلسازی شبیهسازیهای دینامیکی کلیدی، برخی از زمینههای کلیدی هستند که شبکههای عصبی در آنها نفوذ کردهاند. از شبکههای عصبی با تأخیر زمانی میتوان برای مدلسازی سامانههای دینامیکی غیرخطی با زمان استفاده کرد.
شبکههای عصبی با تأخیر زمانی برای تشخیص ویژگی مستقل از موقعیت به کار میروند. بنابراین، الگوریتمی که بر اساس شبکههای عصبی با تأخیر زمانی ساخته میشود، قادر به تشخیص الگوها است (شبکههای عصبی با کپی کردن دادههای اصلی از واحدهای ویژگی، به طور خودکار الگوها را شناسایی میکنند).
علاوه بر این، از شبکههای عصبی با تأخیر زمانی برای بخشیدن دینامیک قویتر به مدلهای شبکه عصبی استفاده میشود. از آنجایی که ایمنی مسافران در داخل هواپیما از اهمیت ویژهای برخوردار است، الگوریتمهای ساختهشده با استفاده از سیستمهای شبکه عصبی، دقت سامانه خلبان خودکار (autopilot) را تضمین میکنند. با توجه به این که اکثر عملکردهای خلبان خودکار به صورت خودکار انجام میشوند، ضروری است راهی برای به حداکثر رساندن امنیت آنها در نظر گرفته شود.
۵- صنایع دفاع
صنایع دفاعی، مهمترین صنعت هر کشوری است. جایگاه هر کشوری در عرصه بینالمللی با ارزیابی عملیات نظامی آن سنجیده میشود. شبکههای عصبی بر عملیات دفاعی کشورهای پیشرفته از نظر فناوری تأثیر میگذارند. ایالات متحده آمریکا، بریتانیا و ژاپن از جمله کشورهایی هستند که از شبکههای عصبی مصنوعی برای توسعه یک استراتژی دفاعی فعال استفاده میکنند.
شبکههای عصبی در لجستیک، تجزیه و تحلیل حملات مسلحانه و برای موقعیتیابی اشیاء به کار گرفته میشوند. همچنین از آنها در گشت هوایی، گشت دریایی و کنترل پهپادهای خودکار استفاده میشود. بخش دفاعی برای ارتقای فناوریهای خود، از هوش مصنوعی که به آن نیاز مبرمی دارد، بهره میبرد.
شبکههای عصبی کانولوشنال (CNN) برای تعیین وجود مینهای زیرآبی به کار میروند. مینهای زیرآبی مسیری زیرزمینی هستند که به عنوان مسیر تردد غیرقانونی بین دو کشور عمل میکنند. وسایل نقلیه دریایی خودکار مانند پهپادهای هوایی (UAV) و زیردریاییهای بدون سرنشین (UUV) از شبکههای عصبی کانولوشنال برای پردازش تصویر استفاده میکنند.
لایههای کانولوشنال، اساس شبکههای عصبی کانولوشنال را تشکیل میدهند. این لایهها از فیلترهای مختلفی برای تمایز بین تصاویر استفاده میکنند. همچنین لایهها دارای فیلترهای بزرگتری هستند که کانالها را برای استخراج تصویر فیلتر میکنند.
۶- بهداشت و سلامت
همانطور که ضربالمثل قدیمی میگوید «سلامتی، ثروت است». ما مردم امروزی به خوبی از مزایای فناوری در بخش مراقبتهای بهداشتی استفاده میکنیم. شبکههای عصبی کانولوشنال (CNN) به طور فعال در صنعت مراقبتهای بهداشتی برای تشخیص اشعه ایکس، سیتی اسکن و سونوگرافی به کار گرفته میشوند.
از آنجایی که CNN در پردازش تصویر استفاده میشود، دادههای تصویربرداری پزشکی بهدستآمده از آزمایشهای مذکور بر اساس مدلهای شبکه عصبی تجزیه و تحلیل و ارزیابی میشوند. شبکههای عصبی بازگشتی (RNN) نیز برای توسعه سیستمهای تشخیص گفتار به کار گرفته میشوند.
امروزه از سیستمهای تشخیص گفتار برای پیگیری اطلاعات بیمار استفاده میشود. همچنین محققان از شبکههای عصبی تولیدکننده برای کشف دارو استفاده میکنند. مطابقت دادن دستههای مختلف دارو کار سنگینی است، اما شبکههای عصبی تولیدکننده این کار دشوار را تسهیل کردهاند. از آنها میتوان برای ترکیب عناصر مختلف که اساس کشف دارو را تشکیل میدهد، استفاده کرد.
۷- تایید امضا و تحلیل خط
همانطور که از اصطلاح آن مشخص است، تایید امضا برای بررسی امضای فرد به کار میرود. بانکها و سایر موسسات مالی از تایید امضا برای تطبیق هویت فرد استفاده میکنند.
معمولا از نرمافزار تایید امضا برای بررسی امضاها استفاده میشود. با توجه به اینکه موارد جعل امضا در موسسات مالی بسیار رایج است، تایید امضا یک عامل مهم برای بررسی دقیق صحت اسناد امضا شده به شمار میرود.
شبکههای عصبی برای تایید امضا به کار گرفته میشوند. این شبکهها با استفاده از یادگیری ماشین برای تشخیص تفاوت بین امضای واقعی و جعلی آموزش داده میشوند. از شبکههای عصبی میتوان برای تایید امضاهای الکترونیکی و آفلاین استفاده کرد.
مقاله پیشنهادی: امضای الکترونیکی چیست
برای آموزش مدل شبکههای عصبی، مجموعه دادههای متنوعی وارد پایگاه داده میشوند. دادههای ورودی به مدل شبکه عصبی کمک میکنند تا بتواند تمایز قائل شود. مدل شبکه عصبی از پردازش تصویر برای استخراج ویژگیها استفاده میکند.
تحلیل خط در پزشکی قانونی نقش مهمی ایفا میکند. این تحلیل برای ارزیابی تغییرات در دو سند دستنویس استفاده میشود. فرآیند نوشتن کلمات روی یک برگه خالی نیز برای تحلیل رفتار به کار میرود. شبکههای عصبی کانولوشنال (CNN) برای تحلیل خط و تایید خط استفاده میشوند.
۸- پیشبینی آب و هوا
پیشبینیهای انجامشده توسط سازمان هواشناسی پیش از ظهور هوش مصنوعی، هرگز از دقت کافی برخوردار نبودند. پیشبینی آب و هوا عمدتاً برای پیشبینی شرایط جوی پیش رو انجام میشود. در عصر حاضر، از پیشبینیهای آب و هوا حتی برای تخمین احتمال وقوع بلایای طبیعی نیز استفاده میشود.
برای پیشبینی آب و هوا از چندلایه پرسپترون (MLP)، شبکه عصبی کانولوشنال (CNN) و شبکههای عصبی بازگشتی (RNN) استفاده میشود. مدلهای سنتی چندلایه شبکههای عصبی نیز میتوانند شرایط آب و هوایی را تا ۱۵ روز آینده پیشبینی کنند. ترکیبی از انواع مختلف معماری شبکههای عصبی برای پیشبینی دمای هوا به کار میرود.
برای آموزش مدلهای مبتنی بر شبکه عصبی، ورودیهای مختلفی مانند دمای هوا، رطوبت نسبی، سرعت باد و تشعشعات خورشیدی در نظر گرفته میشوند. مدلهای ترکیبی (MLP+CNN) و (CNN+RNN) معمولاً در پیشبینی آب و هوا عملکرد بهتری دارند.
انواع شبکههای عصبی در یادگیری ماشین
در ادامه، به بررسی انواع مختلف شبکههای عصبی در یادگیری ماشین میپردازیم:
۱. شبکه عصبی مصنوعی (ANN)
شبکه عصبی مصنوعی که به اختصار ANN نیز نامیده میشود، به عنوان یک شبکه عصبی پیشخور عمل میکند، زیرا ورودیها در جهت جلو حرکت میکنند. این شبکهها میتوانند لایههای مخفی داشته باشند که مدل را حتی متراکمتر میکند. آنها طول ثابتی دارند که توسط برنامهنویس مشخص میشود. این نوع شبکه برای دادههای متنی یا دادههای جدولی استفاده میشود. یکی از کاربردهای رایج در دنیای واقعی، شناسایی چهره است. از نظر قدرت، این نوع شبکه نسبت به CNN و RNN ضعیفتر است.
۲. شبکه عصبی کانولوشنی (CNN)
شبکههای عصبی کانولوشنی عمدتاً برای دادههای تصویری استفاده میشوند و در بینایی کامپیوتر کاربرد دارند. برخی از کاربردهای دنیای واقعی آن شامل تشخیص اشیا در خودروهای خودران است. این نوع شبکه ترکیبی از لایههای کانولوشنی و نورونها را شامل میشود و از هر دو ANN و RNN قدرتمندتر است.
۳. شبکه عصبی بازگشتی (RNN)
این نوع شبکه که به اختصار RNN نیز شناخته میشود، برای پردازش و تفسیر دادههای زمانی استفاده میشود. در این مدل، خروجی از یک گره پردازشی دوباره به گرههای همان لایه یا لایههای قبلی بازگشت داده میشود. معروفترین نوع RNN، شبکههای LSTM (حافظه بلندمدت و کوتاهمدت) هستند.
انواع یادگیریها در شبکههای عصبی
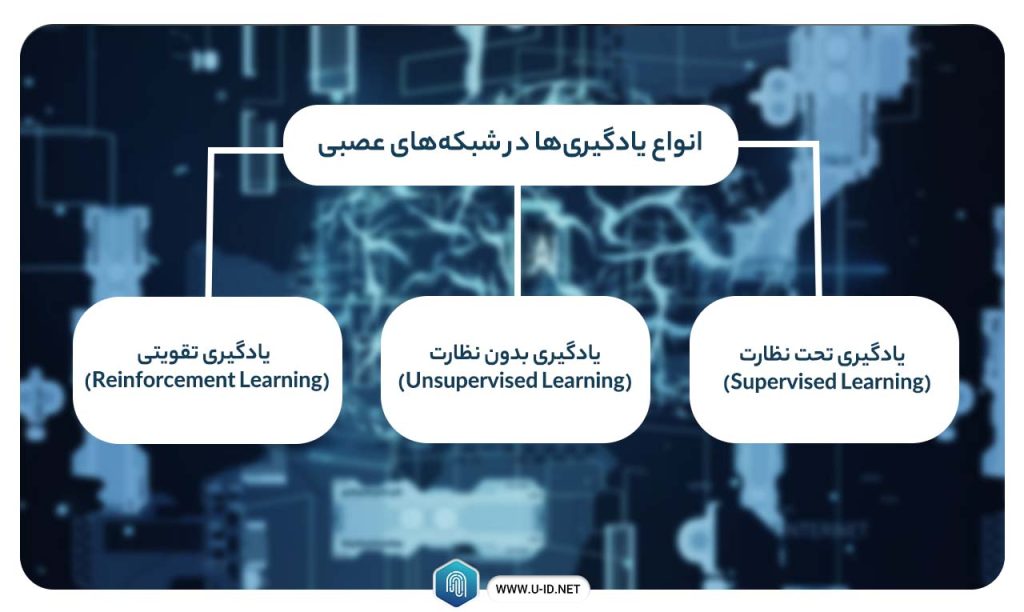
یادگیری در شبکه های عصبی انواع مختلفی دارد که عبارتند از:
- یادگیری تحت نظارت (Supervised Learning)
- یادگیری بدون نظارت (Unsupervised Learning)
- یادگیری تقویتی (Reinforcement Learning)
۱- یادگیری تحت نظارت
همانطور که از نامش پیداست، یادگیری تحت نظارت نوعی یادگیری است که تحت نظر یک ناظر انجام میشود. این نوع یادگیری شبیه به یادگیری با یک معلم است. شما تمام دادهها را از مجموعه داده آموزشی وارد میکنید و وزنهای نهایی شبکه عصبی به همراه معماری آن، شبکه عصبی آموزشدیده را تعریف میکنند. این فرایند شامل آموزش شبکههای عصبی است. این شبکههای عصبی آموزشدیده مسائل خاصی را که در صورتمسئله تعریف شدهاند، حل میکنند. در این نوع یادگیری، بازخوردی از محیط به مدل داده میشود.
۲- یادگیری بدون نظارت
برخلاف یادگیری تحت نظارت، در اینجا هیچ ناظر یا معلمی وجود ندارد. در این نوع یادگیری، بازخوردی از محیط وجود ندارد، خروجی مطلوبی نیز وجود ندارد و مدل بهطور خودکار یاد میگیرد. در مرحله آموزش، شما ورودیها را به کلاسهایی تقسیم میکنید که شباهت اعضای آنها را تعریف میکند. هر کلاس شامل الگوهای ورودی مشابه است. هنگامی که یک الگوی جدید وارد میشود، مدل میتواند براساس شباهت با سایر الگوها پیشبینی کند که آن ورودی به کدام کلاس تعلق دارد. اگر چنین کلاسی وجود نداشته باشد، یک کلاس جدید تشکیل میشود.
۳- یادگیری تقویتی
یادگیری تقویتی بهترین ویژگیهای هر دو نوع یادگیری تحت نظارت و بدون نظارت را ترکیب میکند. این شیوه شبیه به یادگیری با نقد و بررسی است. در این نوع یادگیری، بازخورد دقیقی از محیط وجود ندارد، بلکه بازخورد نقدی دریافت میشود. این نقد به مدل میگوید که چقدر راهحل ما به نتیجه نهایی نزدیک است. بنابراین، مدل بر اساس اطلاعات نقدی بهطور خودکار یاد میگیرد. این نوع یادگیری مشابه یادگیری تحت نظارت است از این جهت که بازخوردی از محیط دریافت میکند، اما تفاوت آن در این است که مدل اطلاعات خروجی مطلوب را دریافت نمیکند، بلکه اطلاعات نقدی را دریافت میکند.
شبکه عصبی عمیق چیست؟
به طور ساده، یک شبکه عصبی با کمی پیچیدگی، که معمولاً حداقل از دو لایه تشکیل شده باشد، به عنوان یک شبکه عصبی عمیق (DNN) یا به اختصار شبکه عمیق شناخته میشود. شبکههای عمیق با استفاده از مدلسازی ریاضی پیچیده، دادهها را به روشهای پیچیدهای پردازش میکنند.
با این حال، برای درک واقعی شبکههای عصبی عمیق، بهتر است آن را به عنوان یک فرآیند تکاملی در نظر بگیریم. پیش از پیدایش شبکههای عمیق، نیاز به ساخت چند عنصر کلیدی وجود داشت.
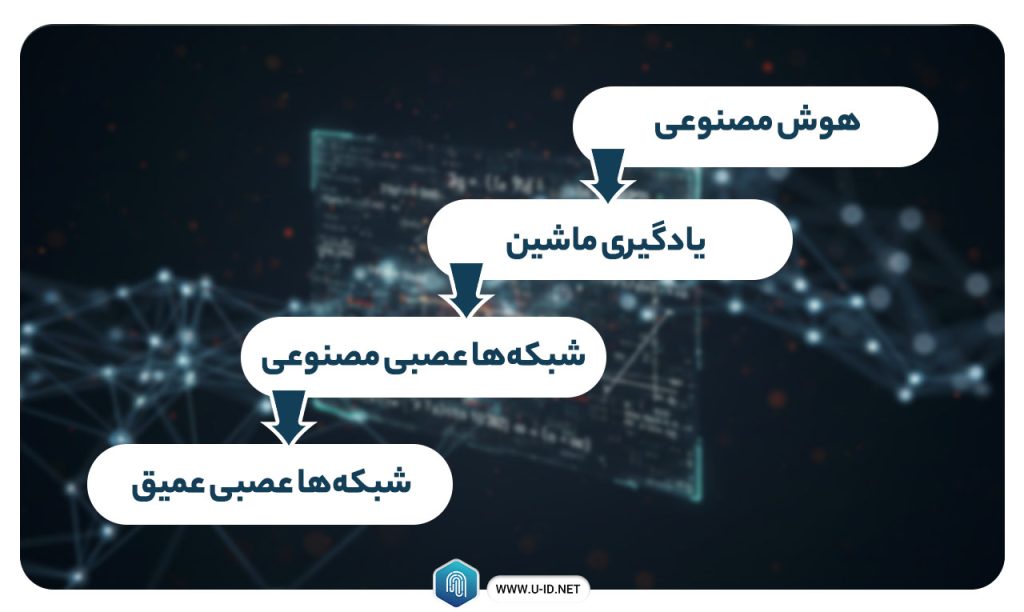
ابتدا، یادگیری ماشینی باید توسعه مییافت. یادگیری ماشینی چارچوبی برای خودکارسازی مدلهای آماری (از طریق الگوریتمها) مانند مدل رگرسیون خطی است تا بتواند در پیشبینی بهتر عمل کند. منظور از مدل، مدلی منفرد است که پیشبینیهایی در مورد موضوعی خاص انجام میدهد. این پیشبینیها با مقداری دقت انجام میشوند. مدلی که یاد میگیرد و آموزش میبیند – یادگیری ماشینی – تمام پیشبینیهای اشتباه خود را درنظر میگیرد و وزنهای درون مدل را تنظیم میکند تا مدلی بسازد که اشتباهات کمتری داشته باشد.
بخش یادگیری در ایجاد مدلها، منجر به توسعه شبکههای عصبی مصنوعی (ANN) شد. شبکههای عصبی مصنوعی از لایه پنهان به عنوان مکانی برای ذخیره و ارزیابی اهمیت هر یک از ورودیها نسبت به خروجی استفاده میکنند. لایه پنهان، اطلاعات مربوط به اهمیت ورودی را ذخیره میکند و همچنین ارتباطهایی بین اهمیت ترکیبات ورودی برقرار میسازد.
شبکههای عصبی عمیق (DNN) بر اساس عنصر شبکههای عصبی مصنوعی (ANN) بنا شدهاند. آنها میگویند که اگر این روش (استفاده از لایه پنهان) باعث بهبود مدل میشود – زیرا هر گره در لایه پنهان، هم ارتباطات را برقرار میکند و هم اهمیت ورودی برای تعیین خروجی را درجهبندی میکند – چرا لایههای بیشتری روی هم قرار ندهیم تا از مزایای بیشتری از لایه پنهان بهرهمند شویم؟
بنابراین، شبکههای عمیق دارای چندین لایه پنهان هستند. «عمیق» به این معناست که مدل دارای چندین لایه زیر هم است.
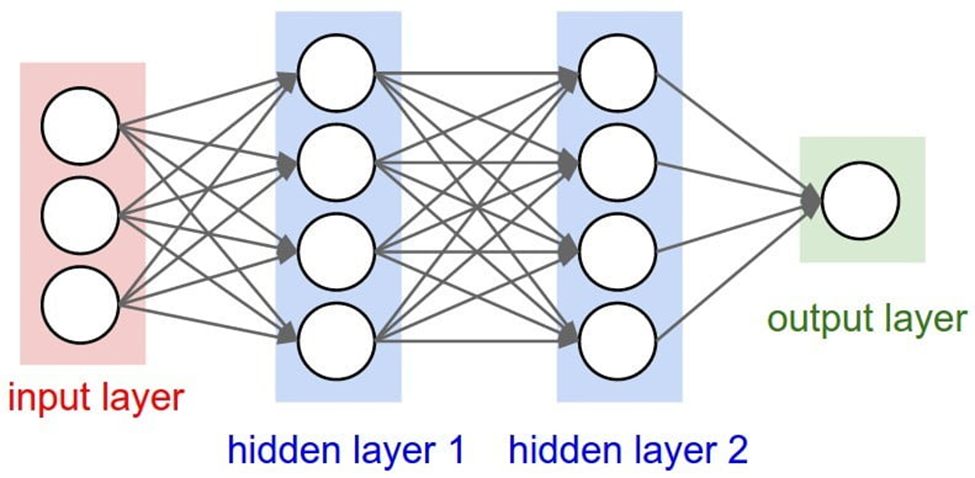
مدلهای شبکههای عصبی عمیق در ابتدا از عصبشناسی الهام گرفته شدهاند. در سطح بالا، یک نورون بیولوژیکی سیگنالهای متعددی را از طریق سیناپسهایی (Synapse یا محل اتصال عصبی) که با دندریتهای (Dendrite) آن در تماس هستند دریافت میکند و یک جریان واحد از پتانسیلهای عمل را از طریق آکسون خود ارسال میکند. پیچیدگی چند ورودی با دستهبندی الگوهای ورودی آن کاهش مییابد. با الهام از این شهود، مدلهای شبکه عصبی مصنوعی از واحدهایی تشکیل شدهاند که ورودیهای متعدد را ترکیب کرده و یک خروجی واحد تولید میکنند.
شبکه عصبی عمیق برای چه مواردی استفاده میشود؟
یکی از اصلیترین کاربردهای این شبکههای پیشرفته، پردازش دادههای بدون ساختار است. شبکههای عصبی عمیق قادرند دادههای ذخیرهشده در یک پایگاه داده را خوشهبندی و طبقهبندی کنند. این قابلیت برای سازماندهی دادهها بدون برچسب یا ساختار، بسیار مفید است.
شبکه عصبی عمیق برای اتوماسیون برخی از وظایف کاری انسانها بسیار مفید است. این فناوری در زمینه نظارت تصویری برای تکنولوژی شناسایی چهره استفاده میشود. خودروهای خودران نیز به این فناوری وابسته هستند. همینطور دستیارهای مجازی مانند سیری و الکسا، یا حتی موتورهای پیشنهاددهنده در نتفلیکس، اسپاتیفای یا آمازون از این تکنولوژی بهره میبرند. بنابراین، بدون اینکه خودتان بدانید، احتمالاً روزانه از محصولات مبتنی بر شبکههای عصبی عمیق استفاده میکنید.
علاوه بر این، یادگیری عمیق در حال گسترش در هر صنعتی است. از این فناوری در حوزه بهداشت برای تشخیص سرطان یا رتینوپاتی استفاده میشود. در صنعت هواپیمایی برای بهینهسازی ناوگان هوایی کاربرد دارد. صنعت نفت و گاز به شبکههای عصبی مصنوعی عمیق برای نگهداری پیشبینیشده ماشینآلات روی آورده است. بانکها و خدمات مالی نیز از آن برای شناسایی تقلب استفاده میکنند. به تدریج، یادگیری عمیق در حال تحول تمامی بخشهای فعالیت است.
شبکههای عصبی عمیق آخرین حلقه در تکامل هوش مصنوعی هستند. در ابتدا، یادگیری ماشین برای خودکارسازی مدلهای آماری از طریق الگوریتمها بهمنظور پیشبینی بهتر استفاده میشد. یک مدل یادگیری ماشین قادر به انجام پیشبینی برای یک کار خاص است. این مدل بهسادگی با تغییر وزنهای خود در هر پیشبینی اشتباه بهمنظور افزایش دقت، یاد میگیرد.
پس از آن، شبکههای عصبی مصنوعی به وجود آمدند. این شبکهها از یک لایه مخفی برای ذخیره و ارزیابی تأثیر هر ورودی بر خروجی نهایی استفاده میکنند. اطلاعات مربوط به تأثیر هر ورودی، ذخیره و مخفی میشود، همچنین ارتباطات بین دادهها نیز شناسایی میشود. در نهایت، شبکههای عصبی عمیق اختراع شدند. بهجای رضایت از یک لایه مخفی، شبکههای عصبی عمیق با ترکیب لایههای مخفی متعدد برای دستیابی به مزایای بیشتر، پیشرفت کردند.
انواع شبکه عصبی عمیق
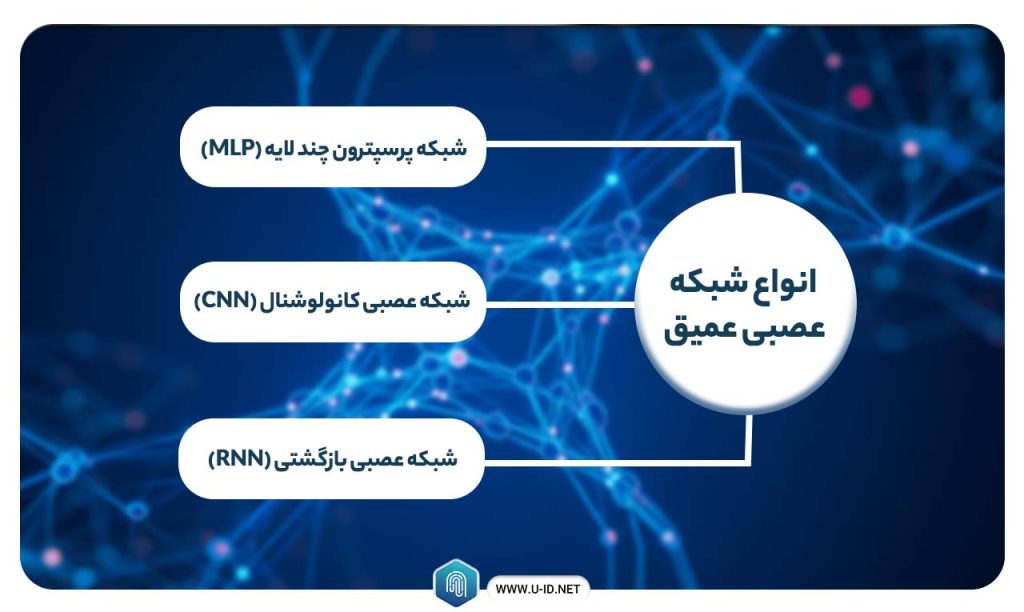
سه نوع رایج از شبکههای عصبی عمیق امروزه مورد استفاده قرار میگیرند:
- شبکه پرسپترون چند لایه (MLP)
- شبکه عصبی کانولوشنال (CNN)
- شبکه عصبی بازگشتی (RNN)
در ادامه، با این شبکههای عصبی عمیق بیشتر آشنا خواهیم شد.
۱- شبکههای پرسپترون چندلایه (MLP)
شبکه پرسپترون چندلایه (MLP) کلاسی از شبکههای عصبی مصنوعی پیشخور (feedforward artificial neural network) است. مدلهای MLP ابتداییترین نوع از شبکههای عصبی عمیق هستند که از مجموعهای از لایههای کاملاً به هم متصل تشکیل شدهاند. امروزه، با استفاده از روشهای یادگیری ماشینی MLP میتوان برای غلبه بر نیاز به قدرت محاسباتی بالا استفاده کرد که در معماریهای یادگیری عمیق مدرن مورد نیاز است.
هر لایه جدید مجموعهای از توابع غیرخطی است که از مجموع وزنی همه خروجیها (کاملاً متصل) از لایه قبل محاسبه میشود.
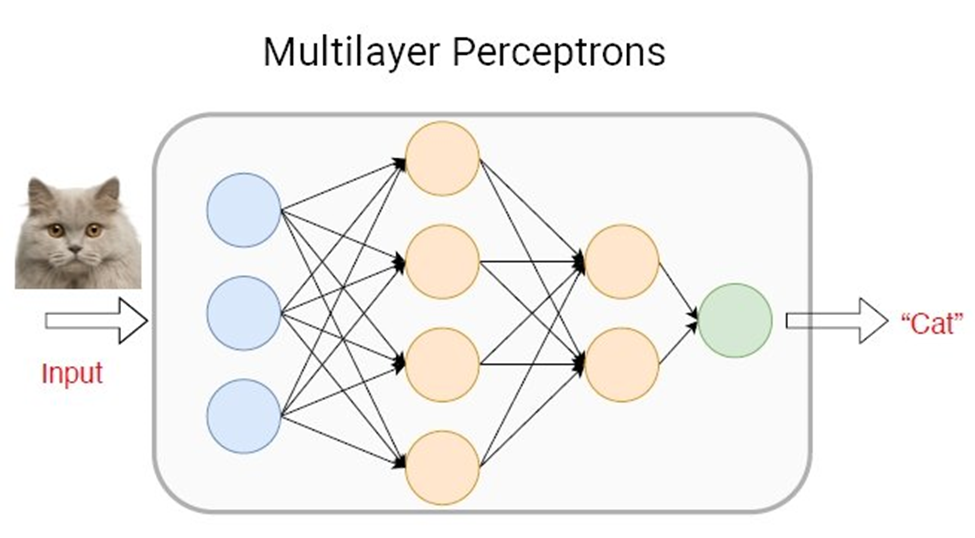
کاربردهای شبکه پرسپترون چندلایه (MLP)
شبکههای پرسپترون چندلایه (MLP) برای کارهایی که با دادههای ساختاریافته سروکار دارند ایدهآل هستند، زیرا میتوانند دادههای ورودی با ابعاد ثابت و ویژگیهای مستقل را مدیریت کنند و به آنها این امکان را میدهند تا الگوها و روابط پیچیده درون دادههای ساختاریافته را بیاموزند. علاوه بر این، قابلیت مقیاسپذیری و سهولت پیادهسازی آنها را برای کارهای مربوط به دادههای ساختاریافته قابل اجرا میکند.
برخی از کاربردهای واقعی MLPها عبارتند از:
- امتیازدهی اعتباری: تجزیه و تحلیل عواملی که به عنوان دادههای ساختاریافته مانند سابقه اعتباری، درآمد و سطح بدهی گردآوری شدهاند تا ارزیابی اعتبارسنجی انجام شود.
- تشخیص تقلب: تجزیه و تحلیل تراکنشها به صورت دادههای جدولی برای شناسایی فعالیتهای بالقوه متقلبانه ، مانند دسترسی غیرمجاز، سرقت هویت، احراز هویت جعلی یا الگوهای خرج غیرمعمول.
- پیشبینی خروج مشتری: تجزیه و تحلیل رفتار مشتری، سابقه خرید و معیارهای تعامل برای شناسایی مشتریانی که در معرض ترک کردن هستند.
۲- شبکه عصبی کانولوشنال (CNN)
شبکه عصبی کانولوشنال (CNN) یا (ConvNet) نوع دیگری از شبکههای عصبی عمیق است. CNNها معمولاً در پردازش تصویر به کار گرفته میشوند. با استفاده از یک سری تصاویر یا ویدیوهای دنیای واقعی و با به کارگیری CNN، سیستم هوش مصنوعی استخراج خودکار ویژگی را از این ورودیها برای تکمیل یک کار خاص، مانند طبقهبندی تصویر، تایید چهره و بخشبندی معنایی تصویر یاد میگیرد.
برخلاف لایههای کاملاً متصل در MLPها، در مدلهای CNN، یک یا چند لایه کانولوشن با اجرای عملیات کانولوشن، ویژگیها را از ورودی استخراج میکنند. هر لایه، مجموعهای از توابع غیرخطی از مجموعهای وزنی در مختصات مختلف زیرمجموعههای فضایی خروجیهای لایه قبل است که امکان استفاده مجدد از وزنها را فراهم میکند.
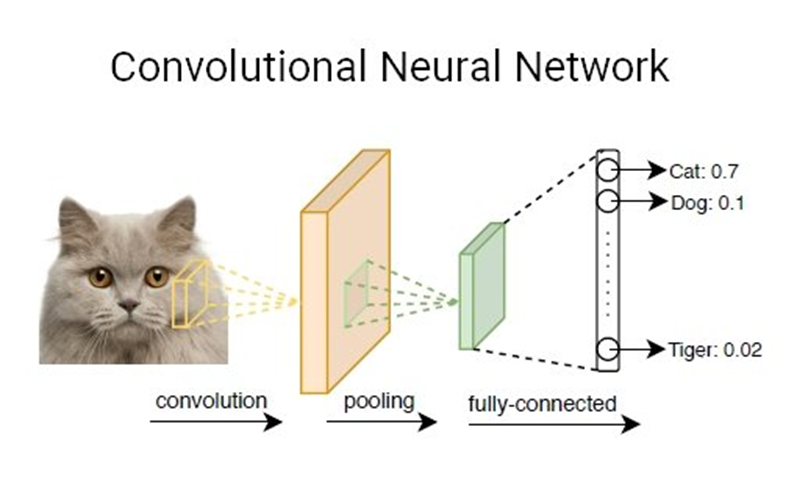
با به کارگیری فیلترهای کانولوشن متنوع، مدلهای یادگیری ماشین CNN میتوانند نمایش سطح بالایی از دادههای ورودی را استخراج کنند و این امر باعث شده است که تکنیکهای CNN در کارهای پردازش تصویر به طور گستردهای مورد استفاده قرار گیرند.
نمونههایی از مدلهای شبکه عصبی کانولوشنال (CNN)
کاربردهای نمونه شبکههای عصبی کانولوشنال شامل طبقهبندی تصویر (به عنوان مثال، AlexNet، شبکه VGG، ResNet، MobileNet) و تشخیص اشیاء (به عنوان مثال، Fast R-CNN، Mask R-CNN، YOLO، SSD) میشود.
- AlexNet: در زمینه طبقهبندی تصویر، AlexNet به عنوان اولین شبکه عصبی کانولوشنال که در سال ۲۰۱۲ برنده چالش ImageNet شد، از پنج لایه کانولوشن و سه لایه کاملاً متصل تشکیل شده است. بنابراین، AlexNet برای طبقهبندی تصویری به اندازه ۲۲۷ در ۲۲۷ به ۶۱ میلیون وزن و ۷۲۴ میلیون محاسبه ضرب و جمع (MAC) نیاز دارد.
- VGG-16: برای دستیابی به دقت بالاتر، VGG-16 برای یک ساختار عمیقتر از ۱۶ لایه متشکل از ۱۳ لایه کانولوشن و سه لایه کاملاً متصل آموزش داده میشود. این مدل برای طبقهبندی تصویری به اندازه ۲۲۴ در ۲۲۴ به ۱۳۸ میلیون وزن و ۱۵.۵ میلیارد محاسبه ضرب و جمع نیاز دارد.
- GoogleNet: برای بهبود دقت و در عین حال کاهش محاسبات استنتاج DNN، GoogleNet یک ماژول inception متشکل از فیلترهای با اندازههای مختلف معرفی میکند. در نتیجه، GoogleNet در مقایسه با VGG-16 به عملکرد دقت بالاتری دست مییابد، در حالی که تنها به هفت میلیون وزن و ۱.۴۳ میلیارد محاسبه ضرب و جمع برای پردازش تصویری با همان اندازه نیاز دارد.
- ResNet: شبکه عصبی رزنت، که یک تلاش پیشرو در این زمینه است، از ساختار میانبر برای دستیابی به دقتی در سطح انسان با نرخ خطای کمتر از ۵ درصد برای پنج دسته برتر استفاده میکند. علاوه بر این، ماژول میانبر میتواند مشکل محو شدن گرادیان را در طول آموزش مدل حل کند و امکان آموزش یک مدل DNN با ساختار عمیقتر را فراهم آورد.
عملکرد CNNهای محبوب به کار رفته در وظایف بینایی هوش مصنوعی در طول سالها به تدریج افزایش یافته است. در حال حاضر، CNNها از بینایی انسان (نرخ خطای ۵ درصد در نمودار زیر) فراتر رفتهاند.
کاربردهای شبکههای عصبی کانولوشنال (CNN)
شبکههای عصبی کانولوشنال (CNN) برای کارهایی مفیدند که شامل ساختار فضایی یا سلسله مراتبی دادههای ورودی مانند دادههای تصویری، صوتی یا سری زمانی هستند. این مدلها برای طبقهبندی تصویر، تشخیص اشیاء و بخشبندی تصویر که در آنها روابط فضایی بین پیکسلها یا ویژگیها اهمیت دارد، بسیار کاربردی هستند. CNNها به طور خودکار ویژگیهای سلسله مراتبی را از دادههای ورودی خام استخراج میکنند و این ویژگی آنها را برای وظایفی که نیازمند استخراج ویژگی از ورودیهای پیچیده هستند، ایدهآل میسازد.
در اینجا چند نمونه از کاربردهای شبکههای عصبی کانولوشنال در دنیای واقعی آورده شده است:
- بازسازی و نگهداری آثار هنری: با تجزیه و تحلیل تصاویر با رزولوشن بالا از نقاشیها یا مجسمهها، CNNها میتوانند قسمتهای گمشده یا فرسوده آثار هنری را تشخیص دهند و بدین ترتیب به بازسازی بخشهای آسیبدیده آثار هنری کمک کنند.
- حفاظت از حیات وحش: متخصصان حفاظت از محیط زیست میتوانند از شبکههای عصبی کانولوشنال برای تجزیه و تحلیل تصاویر تلههای دوربین از راه دور استفاده کنند. با استفاده از تصاویر مکانهای دورافتاده، دیگر نیازی به سفرهای سخت انسان به مناطق صعبالعبور یا دارای حیات وحش نیست. تصاویر این مکانها میتوانند برای ردیابی حیوانات، تخمین اندازه جمعیت و شناسایی فعالیتهای شکار غیرمجاز مورد استفاده قرار گیرند.
- پیشبینی طراحی و ترندهای مد: CNNها را میتوان با مجموعه دادههایی از تصاویر نمایش مد، رسانههای اجتماعی و وبسایتهای تجارت الکترونیک آموزش داد. با استفاده از این اطلاعات، CNNها میتوانند ترندهای نوظهور مد را شناسایی کنند، سبکها را پیشبینی کنند و توصیههای شخصی برای لباس و استایل ارائه دهند.
۳- شبکههای عصبی بازگشتی (RNN)
شبکه عصبی بازگشتی (RNN) کلاس دیگری از شبکههای عصبی مصنوعی است که از تغذیه دادههای ترتیبی استفاده میکند. RNNها برای رسیدگی به مشکل سریهای زمانی در دادههای ورودی ترتیبی توسعه یافتهاند.
ورودی RNN از ورودی فعلی و نمونههای قبلی تشکیل شده است. بنابراین، اتصالات بین گرهها یک گراف جهتدار را در طول یک توالی زمانی تشکیل میدهند. علاوه بر این، هر نرون در یک RNN دارای حافظه داخلی است که اطلاعات محاسبات نمونههای قبلی را حفظ میکند.
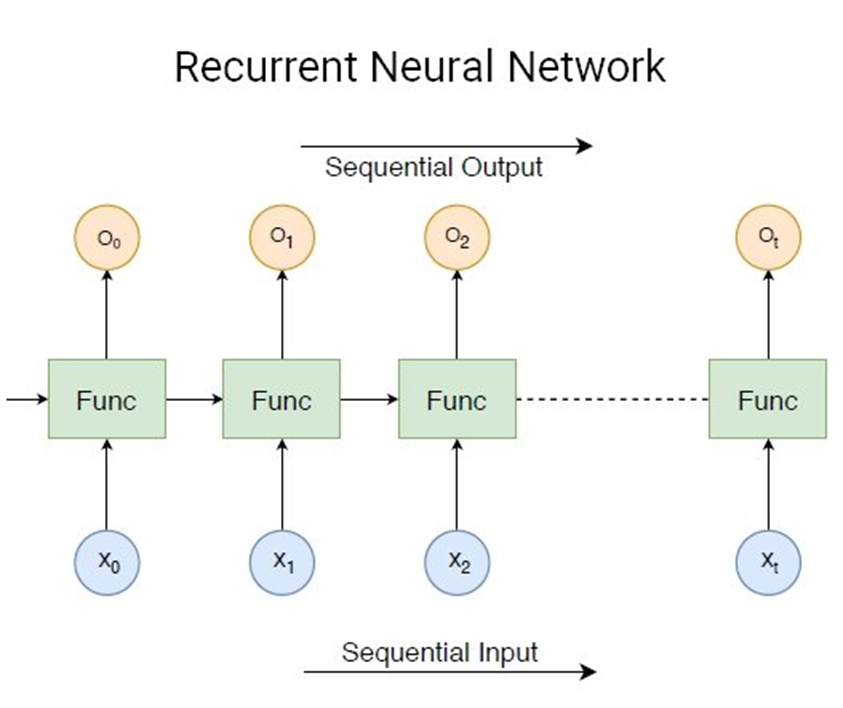
شبکههای عصبی بازگشتی (RNN) به دلیل برتری در پردازش دادههایی با طول ورودی غیرثابت، به طور گسترده در پردازش زبان طبیعی (NLP) مورد استفاده قرار میگیرند. وظیفه هوش مصنوعی در اینجا ساخت سیستمی است که بتواند زبان طبیعی انسان را درک کند. به عنوان مثال، مدلسازی زبان طبیعی، جاسازی کلمات و ترجمه ماشینی.
در RNNها، هر لایه بعدی مجموعهای از توابع غیرخطی از مجموع وزنی خروجیها و حالت قبلی است. بنابراین، واحد پایه RNN یک “سلول” است که از لایهها و مجموعهای از سلولها تشکیل شده است و امکان پردازش ترتیبی مدلهای شبکه عصبی بازگشتی را فراهم میکند.
نمونههایی از مدلهای شبکه عصبی بازگشتی (RNN)
- حافظه بلند مدت (LSTM): مدلهای LSTM مشکل محو شدن گرادیان را که در RNNهای ساده وجود دارد، برطرف میکنند. گنجاندن سلولهای حافظه تخصصی و مکانیزمهای گیتینگ(gating mechanisms) امکان یادگیری وابستگیهای بلندمدت در دادههای ترتیبی را فراهم میکند.
- واحد بازگشتی گیتدار (GRU): شبکههای GRU یا شبکه عصبی واحد بازگشتی دروازهدار، مشابه LSTMها، وابستگیهای دوربرد در دادههای ترتیبی را تشخیص میدهند. معماری GRU در مقایسه با LSTMها سادهتر است و پارامترهای کمتری دارد و در نتیجه در برخی موارد از نظر محاسباتی کارآمدتر است.
- RNNهای دوطرفه: توالیهای ورودی را هم به صورت جلو به عقب و هم عقب به جلو پردازش میکنند و به آنها اجازه میدهند تا وابستگیها را از زمینههای گذشته و آینده به دست آورند. این امر آنها را برای کارهایی مانند تشخیص گفتار و ترجمه ماشینی مفید میسازد.
کاربردهای شبکههای عصبی بازگشتی (RNN)
شبکههای عصبی بازگشتی (RNN) برای دادههای توالیدار یا دادههایی با وابستگیهای زمانی مانند دادههای سری زمانی، متن یا گفتار، مفید هستند. با در نظر گرفتن این موضوع، وظایف RNN ترتیب داده ورودی را در نظر میگیرند، از جمله مدلسازی زبان، تحلیل احساسات و ترجمه ماشینی. RNNها میتوانند پویاییهای زمانی و وابستگیهای دوربرد را در دادههای توالیدار ثبت کنند و به همین دلیل آنها را برای کارهایی که شامل پیشبینی یا تولید توالی میشوند، باارزش میسازند. نمونههایی از کاربردهای RNN در دنیای واقعی عبارتند از:
- ساخت و تولید موسیقی: شبکههای عصبی بازگشتی میتوانند با تحلیل الگو و ساختار موسیقی موجود در دادههای موسیقی، موسیقی جدیدی را با تقلید از ژانرها یا آهنگسازان مختلف تولید کنند.
- قصهگویی شخصیسازیشده و داستانهای تعاملی: RNNها با تحلیل ورودیها و تعاملات کاربر، میتوانند خط فکری داستان، شخصیتها و پیچیدگیها داستانی ایجاد کنند که بر اساس تصمیمات کاربر تطبیق داده شده و تکامل مییابند.
- بازیهای ماجراجویی پیشبینیکننده بر اساس متن: RNNها با تحلیل اقدامات و انتخابهای گفتگو، میتوانند بر اساس تصمیمات بازیکنان، قواعد بازی، تعاملات شخصیتها و روایتهایی را تولید کنند.
تفاوت شبکه عصبی و یادگیری ماشین

یادگیری ماشین، زیرمجموعهای از هوش مصنوعی است که به کامپیوترها این امکان را میدهد تا بدون برنامهریزی صریح از دادهها بیاموزند. شبکههای عصبی نوع خاصی از مدلهای یادگیری ماشین هستند که برای تصمیمگیری شبیه مغز انسان مورد استفاده قرار میگیرند.
به عبارت دیگر، یادگیری ماشین یک مفهوم گستردهتر است که شامل انواع مختلفی از الگوریتمها میشود که میتوانند از دادهها یاد بگیرند. شبکههای عصبی یکی از این الگوریتمهای یادگیری ماشین هستند که با الهام از ساختار و عملکرد مغز انسان طراحی شدهاند.
و در پایان این که…
در این مطلب به بررسی نقش شبکه عصبی در یادگیری ماشینی پرداختیم و به سوالات مختلفی از جمله تفاوت این دو با هم اشاره کردیم. اگر شما هم در زمینه یادگیری ماشین، هوش مصنوعی، شبکههای عصبی و شبکههای عصبی عمیق سوال یا نظری دارید، در بخش دیدگاهها با ما در میان بگذارید.
سوالات متداول
شبکه عصبی که به عنوان شبکه عصبی مصنوعی (ANN) هم شناخته میشود، مدلی است که از ساختار و عملکرد مغز انسان الهام گرفته شده است. این شبکهها از تعداد زیادی واحد پردازش به نام “نورون” تشکیل شده اند که به هم متصل هستند.
یادگیری ماشین یک زمینه ی گسترده تر است که به کامپیوترها این امکان را می دهد تا بدون برنامه نویسی صریح از دادهها آموزش ببینند. شبکههای عصبی نوع خاصی از الگوریتمهای یادگیری ماشین هستند که برای حل مسائلی که نیاز به یادگیری الگوهای پیچیده دارند، مانند تشخیص تصویر، پردازش زبان طبیعی و … مناسب هستند.
شبکه های عصبی مزایای متعددی نسبت به سایر الگوریتم های یادگیری ماشین دارند، از جمله توانایی یادگیری الگوهای پیچیده، انعطافپذیری در حا مسائل مختلف وتوانایی یادگیری از دادههای کلان.
شبکههای عصبی مصنوعی (ANNs) از گرهها یا نورونهای مصنوعی تشکیل شدهاند که با یکدیگر همکاری میکنند تا دادهها را پردازش کنند و از آنها یاد بگیرند. هر گره در یک شبکه عصبی مصنوعی شامل یک تابع فعالسازی است که تعیین میکند چگونه ورودیهای خود را پردازش کند. این تابع فعالسازی میتواند خطی یا غیرخطی باشد، با توجه به نوع مسئلهای که قرار است حل شود.
شبکههای عصبی با انتقال رو به جلو ورودیها، وزنها و بایاسها کار میکنند. با این حال، فرآیند معکوس بازپسانتشار (Backpropagation) جایی است که شبکه در واقع یاد میگیرد. در این فرآیند، شبکه تغییرات دقیق مورد نیاز در وزنها و بایاسها را برای تولید یک نتیجه دقیق تعیین میکند.
یک شبکه عصبی یک برنامه یا مدل یادگیری ماشینی است که به روشی مشابه مغز انسان تصمیمگیری میکند. این مدل با استفاده از فرآیندهایی که نحوه همکاری نورونهای زیستی برای شناسایی پدیدهها، سنجش گزینهها و رسیدن به نتایج را تقلید میکنند، عمل مینماید.







1 دیدگاه دربارهٔ «نقش شبکه عصبی در یادگیری ماشینی چیست»
ممنون از توضیحاتتون